文章摘要
【关 键 词】 AI模型、开源、性能优越、参数优化、成本效益
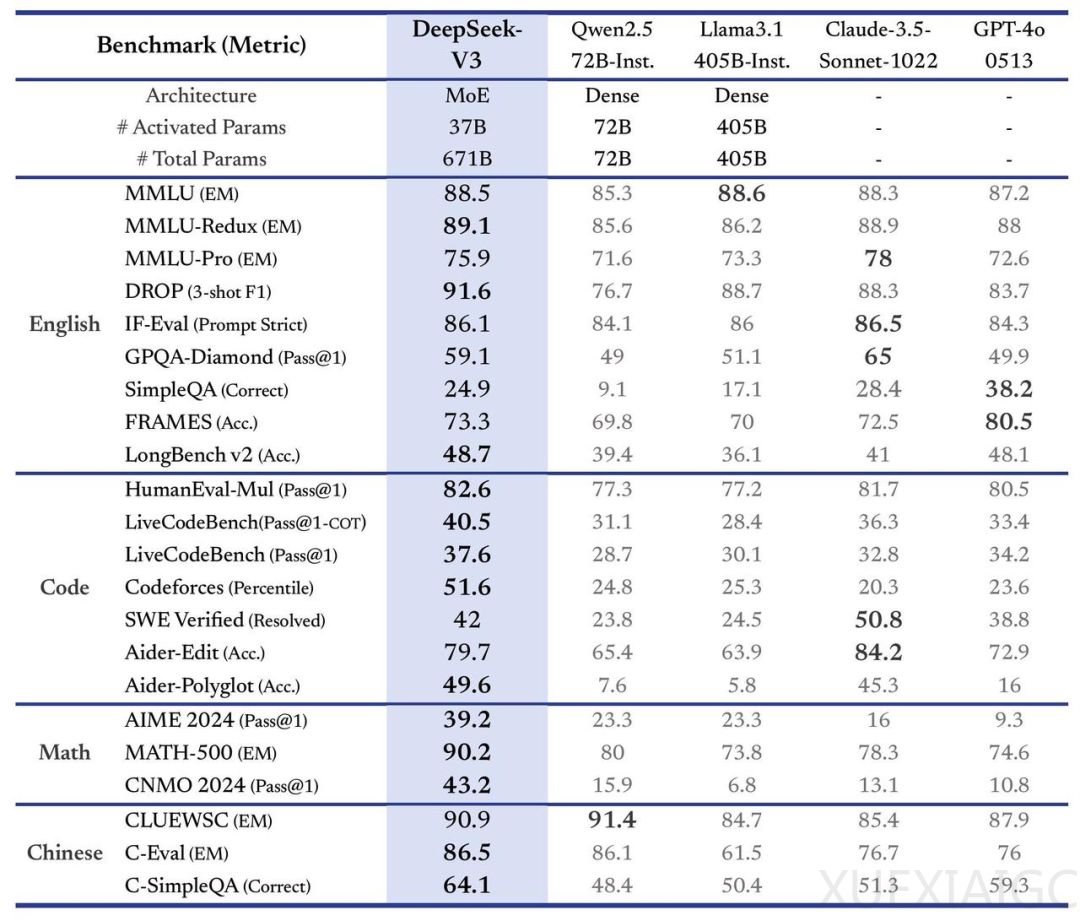
中国AI初创公司DeepSeek发布了其最新人工智能模型DeepSeek-V3的首个版本,并宣布开源。该模型能够处理多种基于文本的工作负载和任务,包括编码、翻译和撰写论文等。DeepSeek-V3在内部基准测试中显示出优于其他公开和封闭AI模型的性能,特别是在编程竞赛平台Codeforces的编码竞赛中,超越了Meta的Llama 3.1 405B、OpenAI的GPT-4o和阿里巴巴的Qwen 2.5 72B等模型。此外,DeepSeek-V3在Aider Polyglot测试中也展现了其编写新代码并整合到现有代码中的能力。
DeepSeek-V3拥有6710亿参数,通过混合专家架构激活选定参数以高效处理任务。模型代码可在GitHub上基于MIT许可获取,企业也可以通过DeepSeek Chat平台测试新模型并访问API进行商业使用。DeepSeek-V3基于多头潜在注意力(MLA)与DeepSeekMoE构建,保持了高效的训练与推理能力,并通过共享“专家”激活370亿个参数。
DeepSeek还推出了两项创新以提高模型表现:辅助无损负载均衡策略和多token预测(MTP),后者使模型训练效率提高,执行速度提升三倍,每秒可生成60个token。DeepSeek-V3在预训练期间训练了14.8T高质量多样化的token,并进行了上下文长度扩展和后训练,包括监督微调和强化学习,以确保与人类偏好一致。
在训练阶段,DeepSeek采用了FP8混合精度训练框架和DualPipe算法等硬件及算法优化方法,降低了运行成本。DeepSeek-V3的生成吐字速度从20 TPS提升至60 TPS,训练成本远低于其他大语言模型,约600万美元,而其他模型如Llama-3.1的训练投入估计超过5亿美元。
DeepSeek-V3在多项基准测试中表现优异,尤其在中文和数学为中心的测试中得分高于其他大模型。在Math-500测试中得分高达90.2,远高于排名第二的Qwen的80分。DeepSeek为DeepSeek-V3 API设定的价格与上一代DeepSeek-V2相同,但将在明年2月8日后调整计费标准。
用户对DeepSeek-V3的评价普遍积极,认为其性价比高,且在实际测试中表现出色,能够理解复杂问题并提供简单的解决方案。
原文和模型
【原文链接】 阅读原文 [ 2005字 | 9分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




