文章摘要
【关 键 词】 API缓存、成本节省、长文本处理、技术更新、应用场景
Claude的API新功能——API长文本缓存,允许模型“记住”一整本书或整个代码库,避免了重复输入的需要。这项功能显著降低了处理长文本的延时,并最高可节省90%的成本。谷歌在Gemini更新中首次提出这项功能,随后Kimi和DeepSeek团队也跟进了这一技术。Anthropic公司提到,提示词缓存功能可以让用户使用更长、更有指导性的提示词对模型进行“微调”。
提示词缓存的作用是一次性给模型发送大量prompt,然后让模型记住这些内容,并在后续请求中直接复用,避免了反复输入。缓存的有效期为五分钟,但每读取一次计时都会被重置。Claude官方文档介绍了几个典型的应用场景,包括对话、代码助理、大型文档处理、详细的指令集、搜索和工具调用以及长文本对话。
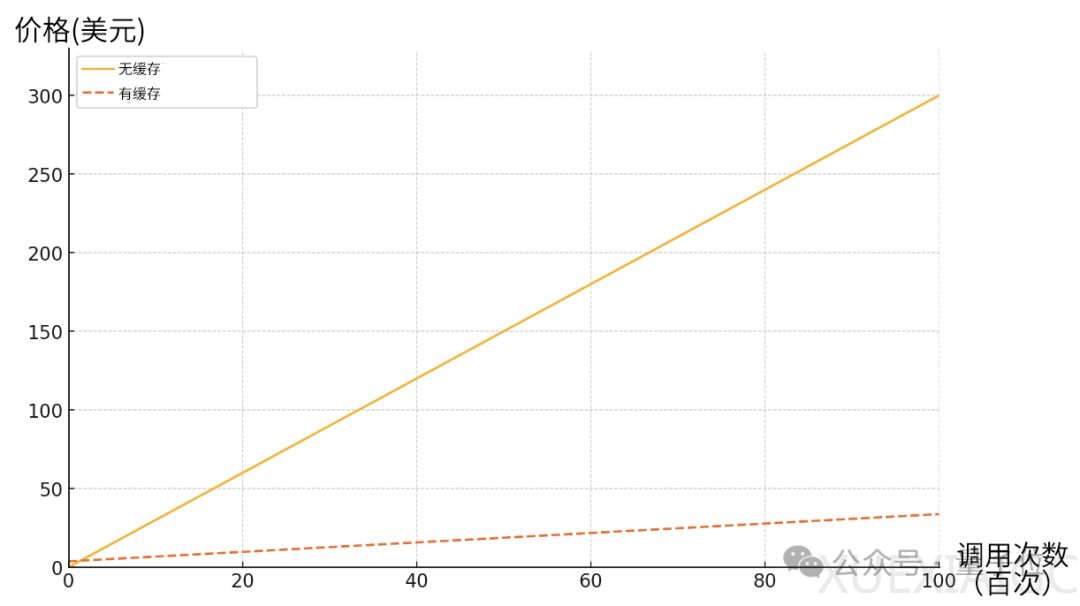
由于不需要反复输入重复的脚本,提示词缓存具有速度更快、成本更低这两大优势。例如,在基于一本10万Tokens的图书进行对话时,使用提示词缓存可以将生成首个输出Token的时间从11.5秒降低到2.4秒,降低了79%,成本更是减少了90%。在其他场景中,延时和成本也有不同程度的降低。
在定价上,原有的输入和输出Token价格不变,提示词缓存的价格则分成了写入和读取两个部分。最小的Haiku每百万Token的写入和读取价格分别是30美分和3美分,3.5 Sonnet分别是3.75美元和0.3美元,最大号的Opus是18.75美元和1.5美元。可以看出,初始写入的价格相对于输入要高一些,但读取的价格只有重复输入的十分之一。缓存被反复读取的次数越多,相比于重新输入节约的成本也就越多。
这项功能对于开发者来说是一项重大利好。AI写作工具HyperWriteAI的创始人兼CEO Matt Shumer表示,这项更新相当重大,意味着人们可以用更低的成本把一整个代码库喂给模型,然后要求增加新功能;或者突破一次只能RAG 5个的限制,直接输入大量文档;又或者直接给出数百个示例,以得到“比微调更好的结果”。
目前该功能支持3 Haiku和3.5 Sonnet,Opus则将在稍晚一些更新。这项功能并非是Claude首创,今年5月,谷歌的Gemini就已经支持了上下文缓存。后来国内的Kimi和DeepSeek团队也进行了跟进。DeepSeek团队把这项技术的存储介质换成了硬盘,还降低了存储成本。触发方式也有所区别,比如DeepSeek是由系统自动判断哪些内容需要缓存,Claude则是要在调用时手动添加标记。虽然在细节上各家有各自的做法,但这种新模式已经受到了国内外顶级玩家的青睐,未来可能会成为大模型厂商的新标配。
原文和模型
【原文链接】 阅读原文 [ 1298字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


