文章摘要
【关 键 词】 视觉识别、开源工具、交互式、OCR识别、AIGC
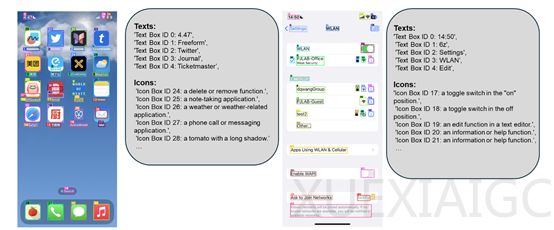
微软研究人员开发了一款名为OmniParser的开源视觉GUI智能体,旨在提升大语言模型(LLM)如GPT-4V在用户界面(UI)识别和操作任务中的表现。OmniParser通过将UI截图解析为结构化元素,增强了模型对界面区域预测的能力,尤其在理解和推理视觉内容方面取得了显著进步。该工具在GitHub上获得了超过3800颗星的关注。
OmniParser的核心组件包括一个微调的交互式图标检测模型、一个微调的图标描述模型以及OCR光学字符识别模块。这些组件共同工作,生成用户界面的结构化表示,并在截图上显示潜在可互动元素的边界框。分阶段处理策略减轻了GPT-4V在动作预测时的负担,使其能更专注于核心任务。
在训练过程中,研究人员利用大规模数据集和Set-of-Marks方法,提高了模型识别多种类型可互动图标的能力。图标描述模型则负责理解图标的功能性语义,而OCR模块则识别和转换图像中的文本内容。OmniParser的集成使得GPT-4V在多个基准测试中性能得到显著提升,超过了同类模型。
OmniParser的开源地址为:https://github.com/microsoft/OmniParser。该工具的开发和开源,为AIGC领域和LLM应用落地提供了重要的技术支持,有助于推动相关技术的发展和应用。
原文和模型
【原文链接】 阅读原文 [ 1703字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...


