开源大模型Llama 3王者归来!最大底牌4000亿参数,性能直逼GPT-4
文章摘要
【关 键 词】 Meta、Llama 3、大模型、开源、AI助手
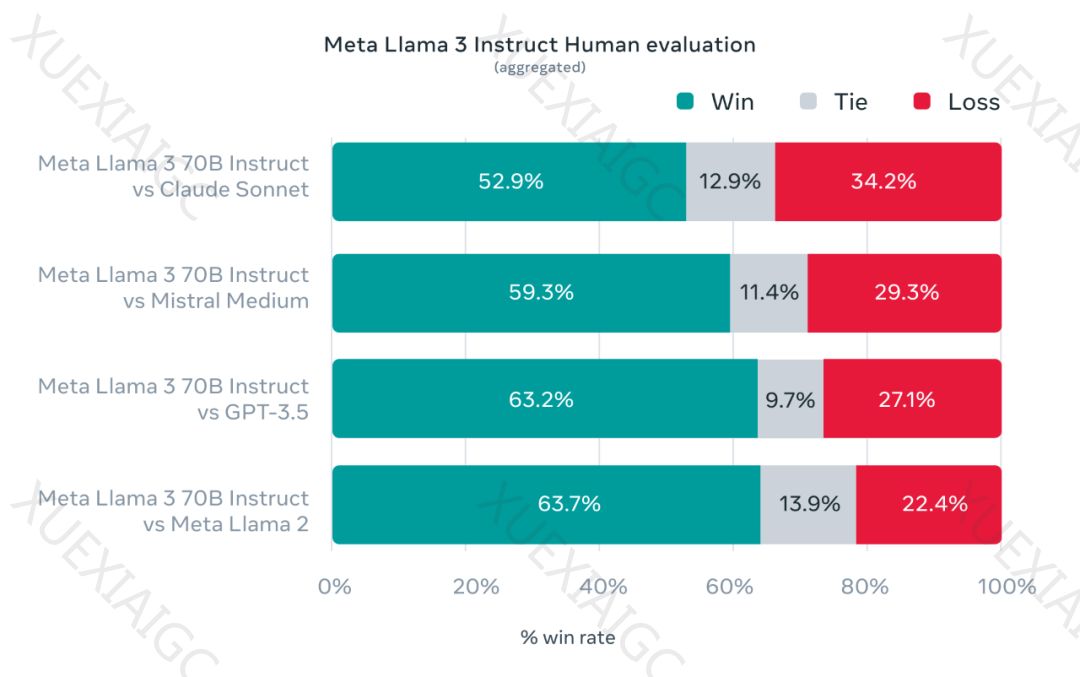
Meta正式发布了备受期待的开源大模型Llama 3,这一举动被视为对ChatGPT的回应,标志着大模型竞赛的加剧。扎克伯格宣布,Llama 3将使Meta的AI助手覆盖其全系应用,并推出了一个基于自然语言提示生成图像的图像生成器。Llama 3的主要特点包括基于超过15T token的训练,支持8K长文本,改进的tokenizer,以及在多个重要基准中展现出的先进性能。此外,Llama 3的训练效率是Llama 2的三倍,并配备了新版的信任和安全工具。
Llama 3的模型架构采用了纯解码器Transformer架构,并进行了关键改进,如使用具有128K token词汇表的tokenizer,以及采用分组查询注意力(GQA)提高推理效率。在训练数据方面,Llama 3使用了超过15T token的数据集,是Llama 2数据集的七倍多,包含四倍多的代码数据。为了确保数据质量,Meta开发了一系列数据过滤pipeline。
在扩展预训练方面,Meta制定了一系列详细的扩展法则,以选择最佳的数据组合,并预测最大模型在关键任务上的性能。Llama 3的训练涉及了数据并行化、模型并行化和管道并行化三种类型的并行化,并在定制的24K GPU集群上进行。
为了充分发挥预训练模型在聊天场景中的潜力,Meta还对指令微调方法进行了创新,结合了有监督微调(SFT)、拒绝采样、近端策略优化(PPO)和直接策略优化(DPO)的组合。这些方法显著提高了模型在推理和编码任务上的性能。
Meta还提供了新的信任与安全工具,如Llama Guard 2、Cybersec Eval 2和Code Shield,以及新的PyTorch原生库torchtune,以便于使用LLM进行创作、微调和实验。此外,Meta还更新了《负责任使用指南》(RUG),为负责任地使用LLM进行开发提供了全面指导。
Llama 3的8B和70B参数模型已经发布,并且Meta正在开发参数超过400B的最大模型,预计在未来几个月内推出。这些模型将包括多模态、多语言对话能力、更长的上下文窗口以及更强的整体能力。一旦完成Llama 3的训练,Meta还将发表一篇详细的研究论文,进一步展示其技术实力。随着生成式人工智能领域的快速发展,开源被视为整合生态系统并减少潜在危害的重要途径。
原文和模型
【原文链接】 阅读原文 [ 3782字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4
【摘要评分】 ★★★★★


相关文章




