文章摘要
【关 键 词】 AI模型、自我纠错、高准确率、开源超越、技术创新
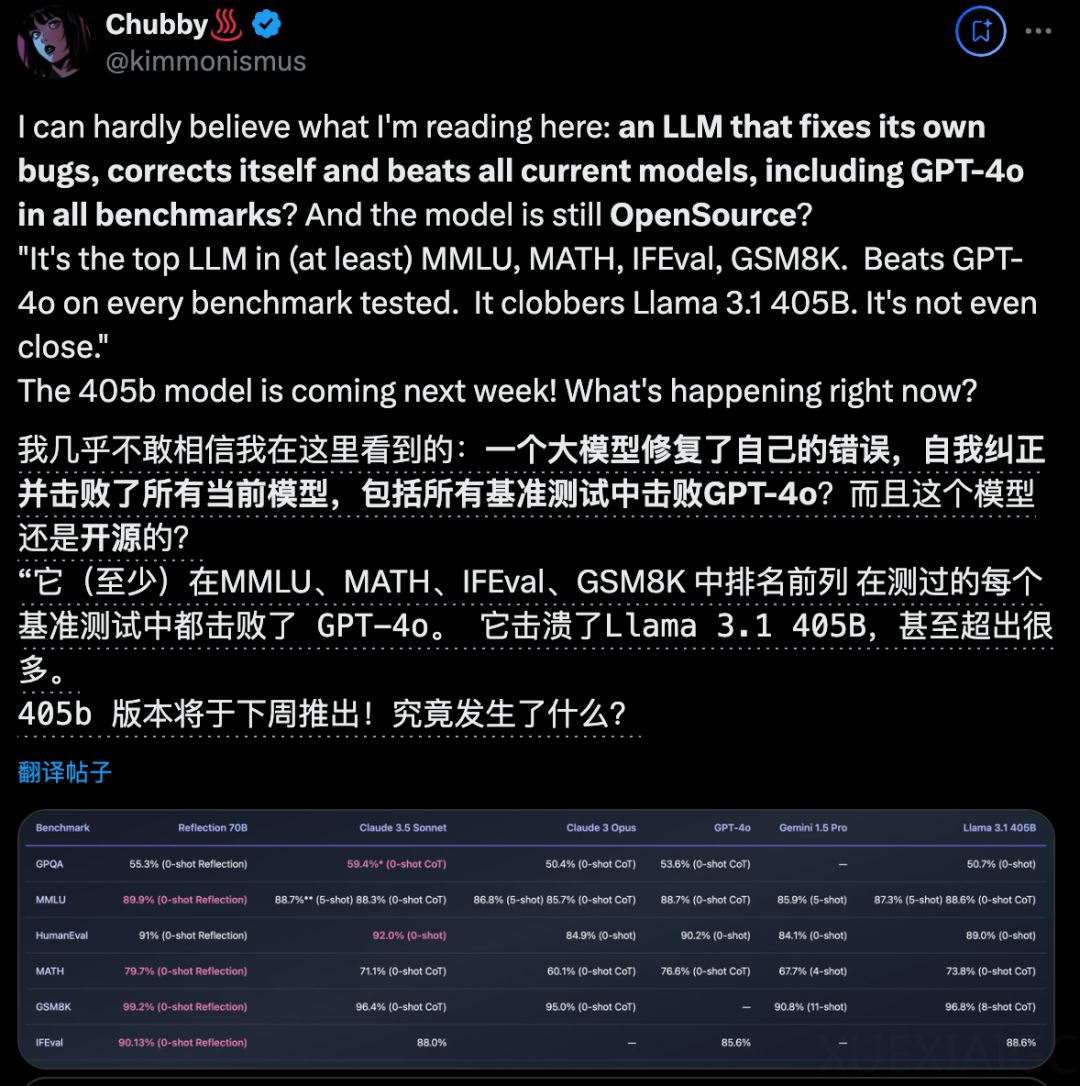
最近,一个名为Reflection 70B的新型人工智能模型在业界引起了巨大轰动。这个由小创业团队开发的模型采用了创新的训练技术Reflection-Tuning,使AI能够在推理过程中自我纠正错误和幻觉。在数r测试中,Reflection 70B展现了其自我纠错的能力,即使在面对错误数据时也能提供正确答案,这表明其99.2%的高准确率并非仅仅依赖于记忆测试集。
在官方评测中,Reflection 70B在多个基准测试中超越了其他顶尖开源模型,包括Llama 3.1 405B、GPT-4o、Claude 3 Opus和Gemini 1.5 Pro。特别是在数学基准GSM8K上,Reflection 70B取得了99.2%的惊人成绩,这一结果甚至引发了OpenAI科学家Noam Brown的讨论,他提出是否应该淘汰这个基准。
模型上线后,网友的试玩热情高涨,Meta公司也提供了额外的算力支持。Reflection 70B不仅能够处理复杂的数学问题,还能准确计算生造词中的字母数量,如“drirrrngrrrrrnnn”中的r的数量。
这个模型的成功也标志着开源模型在性能上超越了顶级闭源模型,现在用户可以在本地运行这个最强的开源模型。而且,这只是一个开始,官方宣布将在下周发布更大规模的Reflection 405B模型,预计其性能将大幅优于现有的Sonnet和GPT-4o。
Reflection 70B的权重已经公开,Hyperbolic Labs将在晚些时候提供API访问。模型的训练细节将在未来发布的报告中详细介绍。Reflection-Tuning训练方法使用GlaiveAI平台生成的合成数据,并且Reflection 70B基于Llama 3.1 70B Instruct,可以使用与其他Llama模型相同的代码和pipeline进行采样。模型还引入了特殊tokens来结构化输出过程,通过在
官方还提供了使用Reflection 70B的建议参数和提示,如设置temperature为0.7,top_p为0.95,并在Prompt末尾附加“Think carefully.”以提高准确性。
Reflection 70B背后的团队由HyperWriteAI的CEO Mutt Shumer领导,他是一位连续创业者,拥有丰富的AI应用开发经验。他的公司OthersideAI致力于开发全球最先进的自动补全工具,而HyperWrite则是一个能够像人一样操作谷歌浏览器完成一系列任务的浏览器操作agent。尽管有Meta的支持,但目前试玩平台暂时无法访问,感兴趣的用户可以关注后续的开放情况。
原文和模型
【原文链接】 阅读原文 [ 1251字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章



