文章摘要
【关 键 词】 AI错误、数字比较、软件版本、提示词技巧、模型局限
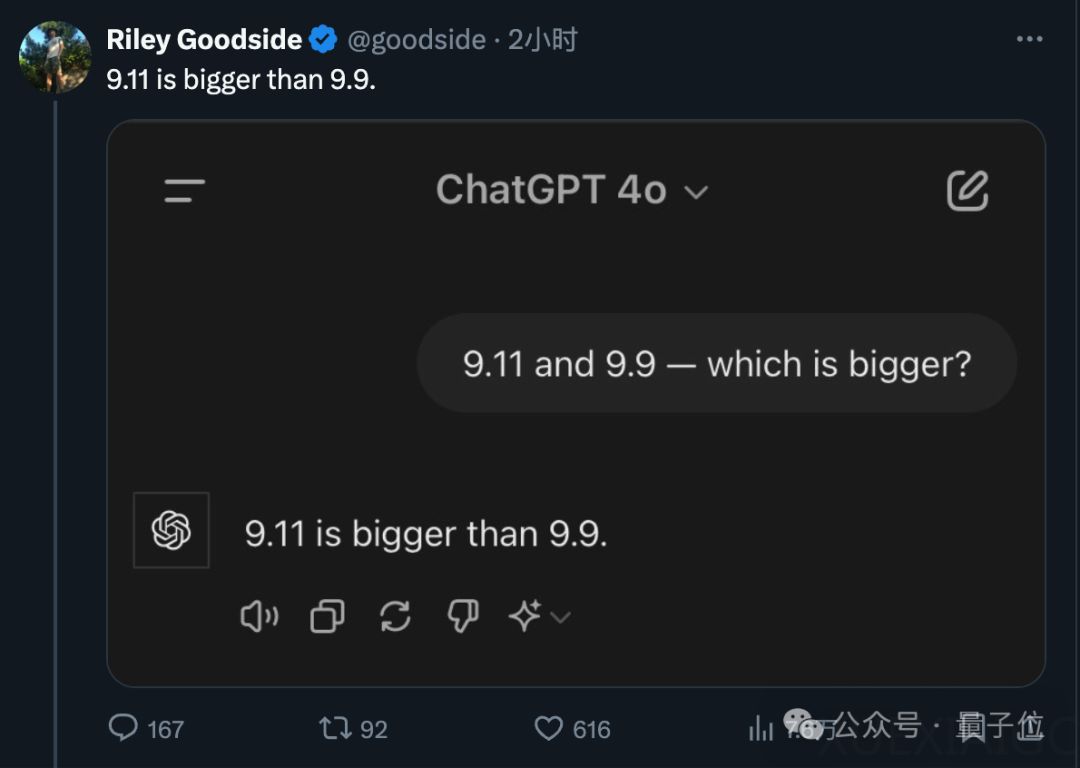
在最近的一项测试中,多个主流大型AI模型在回答“9.11和9.9哪个大”这一简单问题时,意外地给出了错误答案,认为9.11大于9.9。这一现象引起了广泛关注和讨论。Riley Goodside,首位全职提示词工程师,在使用GPT-4o时首次发现了这一问题。他发现,当以特定方式提问时,许多领先的AI模型都会给出错误答案,但改变提问顺序或方式可以避免这一问题。
一些网友推测,AI对词序的敏感性可能是导致这一现象的原因之一。当AI在没有明确目的的情况下接收到数字时,可能会开始“胡思乱想”。此外,还有网友指出,如果将这两个数字视为软件版本号,9.11版本确实比9.9版本更新,这可能与AI是由软件工程师开发的有关。
在对国产大模型的测试中,也出现了类似的错误。例如,Kimi和智谱清言APP上的ChatGLM都直接给出了错误结论。然而,腾讯元宝和字节豆包等少数模型能够正确地描述比较方法并给出正确答案。
分析发现,大模型以token的方式来理解文字,当9.11被拆分为“9”、“小数点”和“11”三部分时,模型错误地认为11大于9,从而导致了这一错误。如果向AI明确解释这是一个双精度浮点数,AI就可以正确地进行比较。
此外,研究者还发现,随着大模型技术的进步,角色扮演提示的作用已经不如最初那么明显。例如,提示“你是一个天才……”的正确率甚至低于“你是一个傻瓜……”。
值得注意的是,尽管OpenAI的新模型在MATH数据集上取得了超过90%的高分,但目前尚不确定该模型能否在没有额外提示的情况下自主解决这一问题。这一现象引发了关于如何引导大模型正确理解问题的讨论,例如使用Zero-shot CoT思维链等方法。
总的来说,这一事件揭示了大型AI模型在理解和处理某些问题时可能存在的局限性,同时也为改进提示词技巧和提高AI的准确性提供了有益的启示。
原文和模型
【原文链接】 阅读原文 [ 1584字 | 7分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




