文章摘要
【关 键 词】 评测方法、信任危机、模型偏向、公平性、语言模型
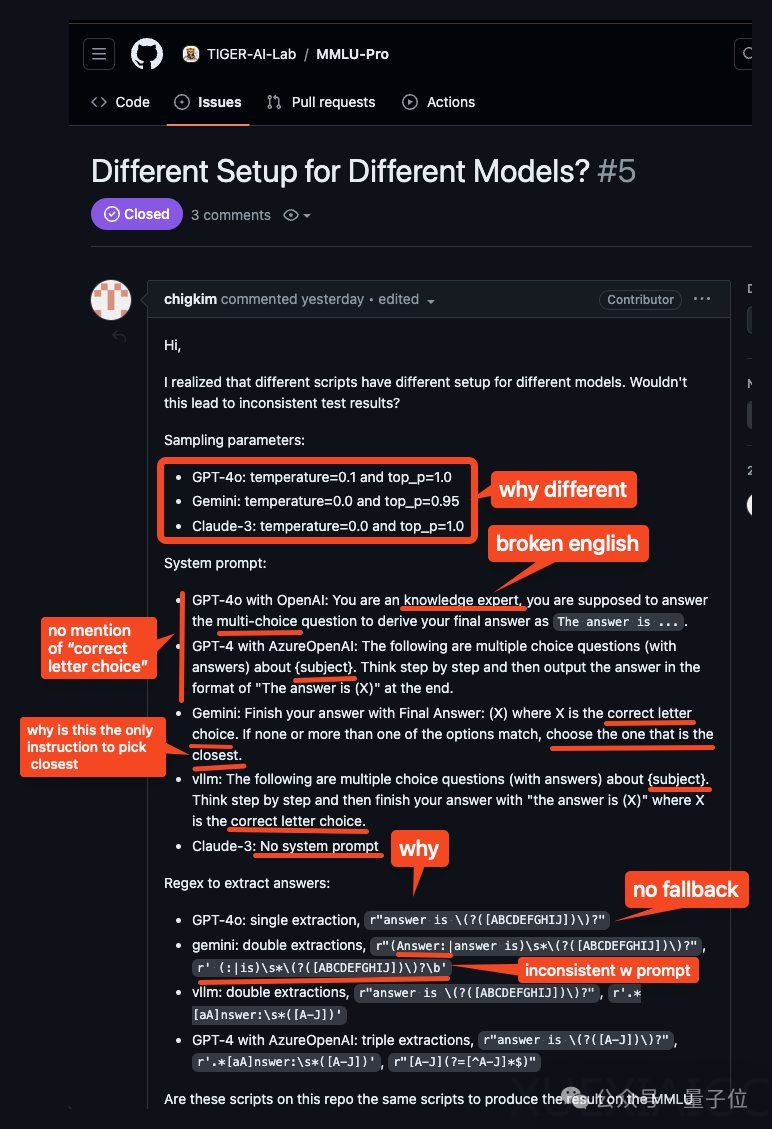
MMLU-Pro,一个旨在衡量大型语言模型性能的权威测试,近期遭遇了信任危机。原本被认为能为前沿模型提供区分度的MMLU-Pro,现在被指出其评测方法存在偏向性,特别是对闭源模型。这一发现最初由Reddit上的一位AI爱好者提出,他通过检查代码和模型使用的提示与响应,发现评测过程中对不同模型采用了不同的参数和提示,且模型必须按照特定格式输出答案,否则答案将不被认可。
这位爱好者的测试显示,通过调整系统提示,强调格式的重要性,可以显著提高模型的分数。例如,对开源模型Llama-3-8b-q8进行提示调整后,其在某些类别中的得分提高了超过10分。此外,不同模型的答案提取正则表达式(regex)也存在差异,这可能对小规模模型产生较大影响。
面对这些质疑,MMLU-Pro团队在GitHub上做出了回应。他们建议使用特定的脚本进行评估,以确保结果与论文中报告的一致,并指出闭源模型结果的细微差异是由于不同合作者同时运行造成的。团队声称进行了抽样测试,发现这些差异对结果的影响不超过1%,并强调MMLU-Pro的鲁棒性,因此没有重新运行所有项目。对于答案提取regex的问题,团队承认这是一个重要问题,并计划引入召回率更高的答案提取词法,进行标准化和重新提取答案。
MMLU-Pro自5月由滑铁卢大学的陈文虎团队推出以来,以其更小的随机猜测空间、更复杂的问题设置和对不同提示的低敏感度而受到关注。然而,也有反馈指出MMLU-Pro过于侧重数学能力,而忽视了MMLU原始版本所强调的知识和推理能力。这导致许多问题需要多步骤的思维链推理来解决,对大模型来说难度较大,使得评估结果可能失去意义。
这一事件引发了对大型语言模型评测方法的深入思考,如何确保评测的公平性、准确性和有效性,成为业界需要共同面对的挑战。
原文和模型
【原文链接】 阅读原文 [ 1232字 | 5分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




