文章摘要
【关 键 词】 AI失智、问题解决、Few-Shot CoT、模型差异、能力边界
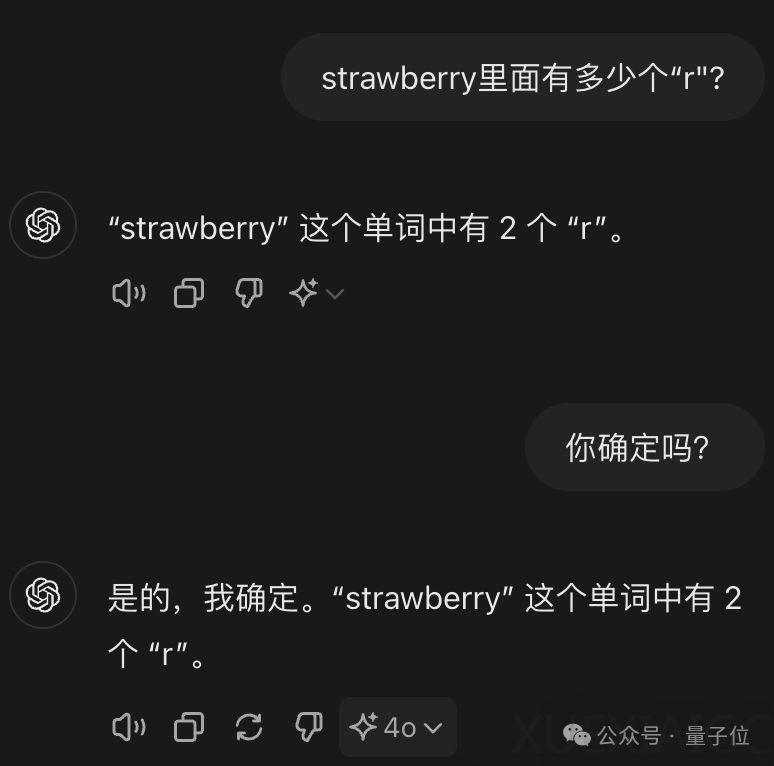
近期,大型AI模型在处理一些看似简单的问题时出现了集体失智的现象,引起了广泛关注和讨论。例如,在计算单词”Strawberry”中”r”的数量时,一些模型给出了错误答案,甚至在纠正过程中越改越错。这并非新问题,但随着新模型的发布,问题再次被放大。
尽管一些AI模型在经过特定提示或训练后能够正确回答,但全球网友和研究者仍在尝试各种方法来解决这一问题。例如,有人利用Few-Shot CoT技术,通过提供人类操作示例来引导AI逐步思考;有人借鉴漫画角色”L”的高智商方法,让AI逐个数出字母并记录位置;还有人通过编写长达3682个token的提示词,引导AI自我发现推理步骤并执行。
值得注意的是,并非所有AI模型都需要额外提示才能正确回答。例如,谷歌的Gemini模型有三分之二的概率能直接答对,而国内的字节豆包、智谱清言的ChatGLM、腾讯元宝、文心一言4.0等模型也能在不同程度上给出正确答案。
究其原因,这些问题对于大模型来说实际上是token问题。单个字符对AI的意义有限,而不同模型的tokenizer会将问题拆分成不同数量的token进行理解。例如,”strawberry”可能被拆分成”st-“、”raw”、”-berry”等部分。此外,特殊字符的引入也会改变token的划分。
解决这一问题的一个简单方法是调用代码。例如,ChatGPT可以直接使用Python的字符串count函数来计算字符数量。关键在于让AI了解自己能力的边界,并主动调用合适的工具。Meta在LLama 3.1论文中也提到了如何教会AI判断自己知道与否。
总的来说,大型AI模型在处理一些看似简单问题时的失智现象,实际上是由于token划分和理解方式的差异导致的。通过提供适当的提示、训练或调用代码等方法,可以提高AI的准确性。同时,让AI了解自己能力的边界并主动调用工具,也是解决这一问题的关键。希望未来的AI模型能够在这些方面取得进步,更好地理解和处理各种问题。
原文和模型
【原文链接】 阅读原文 [ 1262字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


