文章摘要
【关 键 词】 中文问答、语言模型、数据集、真实性评估、技术发展
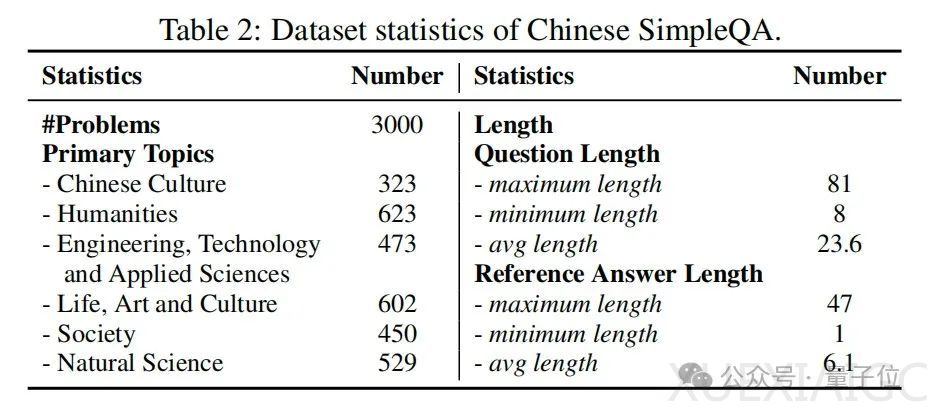
淘宝天猫集团的研究者们最近提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,旨在评估语言模型回答简短问题的真实性能力。该基准具有中文、多样性、高质量、静态、易于评估五个特性,包含3000个高质量问题,涵盖人文到科学工程等6个主要主题。中文简短问答的数据收集过程包括自动构建和人工验证,确保问题和答案的客观性、时效性和挑战性。质量控制流程严格,以保证数据集的准确性。
研究人员对现有大语言模型在中文简短问答上进行了全面评估和分析,发现中文简短问答具有挑战性,只有少数模型达到及格分数。他们还观察到模型越大,性能越好,且更大的模型更校准。此外,检索增强生成(RAG)策略能显著缩小不同大语言模型之间的性能差距。研究还发现,现有的对齐或后训练策略通常会降低语言模型的真实性。中文简短问答与SimpleQA的排名不同,一些专注于中文的大语言模型在特定主题上表现优于GPT或o1系列模型。
中文简短问答的提出,为评估大语言模型在中文语境下的真实性能力提供了重要的工具,有助于推动相关技术的发展。研究人员计划未来研究提高大语言模型的真实性,并探索将中文简短问答扩展到多语言和多模态设置。
原文和模型
【原文链接】 阅读原文 [ 5035字 | 21分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

