文章摘要
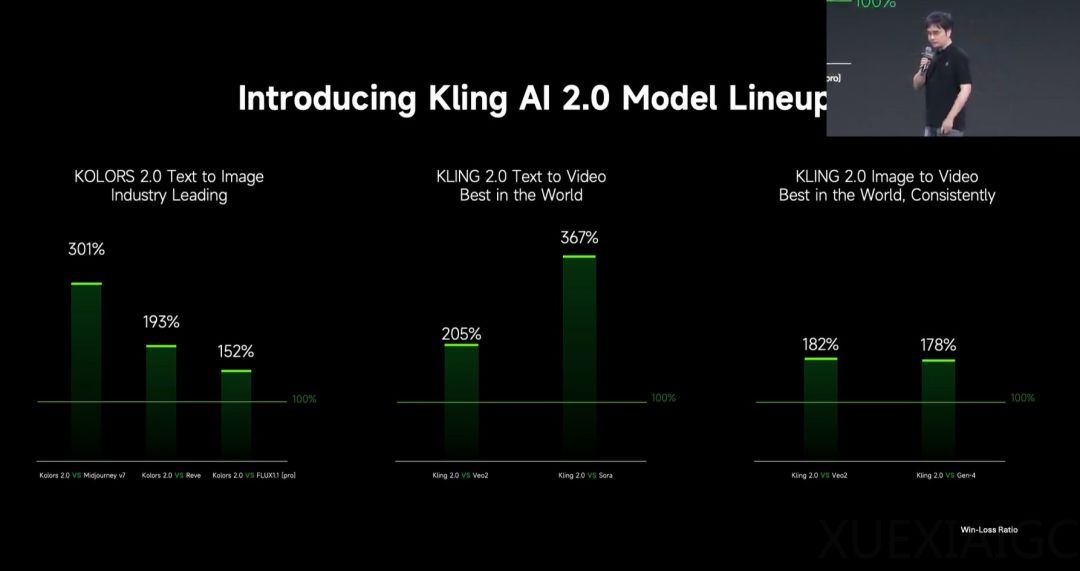
可灵 AI 正式发布了可灵 2.0 视频生成模型和可图 2.0 图像生成模型,标志着其在视觉生成技术领域的重大突破。可灵 2.0 被描述为“世界上最强大的视觉生成模型”,在多项对比测试中表现出色,与 Veo2、Sora、Gen-4 等模型的胜负比均显著高于 100%,显示出其在文生视频和图生视频领域的领先地位。可图 2.0 在文生图方面也取得了显著进展,与 Midjourney v7、Reve 和 Flux 1.1 Pro 的对比测试中同样表现优异。
可灵 2.0 在语义响应、动态质量、真实度和美学优化等方面进行了全面升级。语义响应方面,模型不仅能够更好地理解文本提示,还增强了动作、运镜和时序的响应能力,使得生成的视频更加符合创作者的意图。动态质量方面,模型优化了运动速度的把握,避免了慢动作问题,提升了画面的表现张力。美学优化方面,可灵 2.0 能够生成更具电影质感的镜头,细节表达更加丰富,进一步提升了视觉体验。
可灵 2.0 的技术创新主要体现在基础模型架构和训练推理策略的升级。模型采用了类 Sora 的 DiT 结构,用 Transformer 替代了传统的 U-Net,提升了视觉和文本模态信息的融合能力。此外,模型还通过强化复杂运动、主体交互的生成能力,以及对运镜语言、构图术语的理解,进一步提升了视频表现张力。人类偏好对齐技术的引入,使得模型更懂“常识”和“审美”,生成的内容更符合人类预期。
可图 2.0 在指令遵循、电影质感及艺术风格表现方面也有显著提升。模型支持 60 多种风格化效果转绘,包括 GPT 风格、二次元风格、插画风格等,大幅提升了出图的创意和想象力。快手团队在预训练和后训练阶段进行了大量技术创新,通过精准建模文本到视觉表征的映射,以及强化学习技术的应用,进一步提升了模型的美感和人类审美对齐能力。
可灵 2.0 还引入了多模态编辑功能,支持用户通过图像和视频等多模态信息进行创作。这一功能基于 Multi-modal Visual Language(MVL)理念,将语义骨架和多模态描述子结合,使得用户能够更高效地传达复杂的创意。多模态编辑功能背后是一整套多模态控制技术,包括文本、图像和视觉模态的统一表征,以及高效的 Token 压缩与缓存算法,进一步提升了模型的创作灵活性和稳定性。
可灵 AI 的全球用户规模已突破 2200 万,过去 10 个月里月活用户量增长了 25 倍,累计生成超过 1.68 亿个视频和 3.44 亿张图片。快手团队表示,可灵 2.0 文生视频模型在全球范围内大幅领先,标志着其在视频生成技术领域的持续创新和突破。
原文和模型
【原文链接】 阅读原文 [ 2302字 | 10分钟 ]
【原文作者】 AI前线
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章


