原来,这些顶级大模型都是蒸馏的
文章摘要
【关 键 词】 语言模型、模型蒸馏、响应相似度、身份一致性、数据透明度
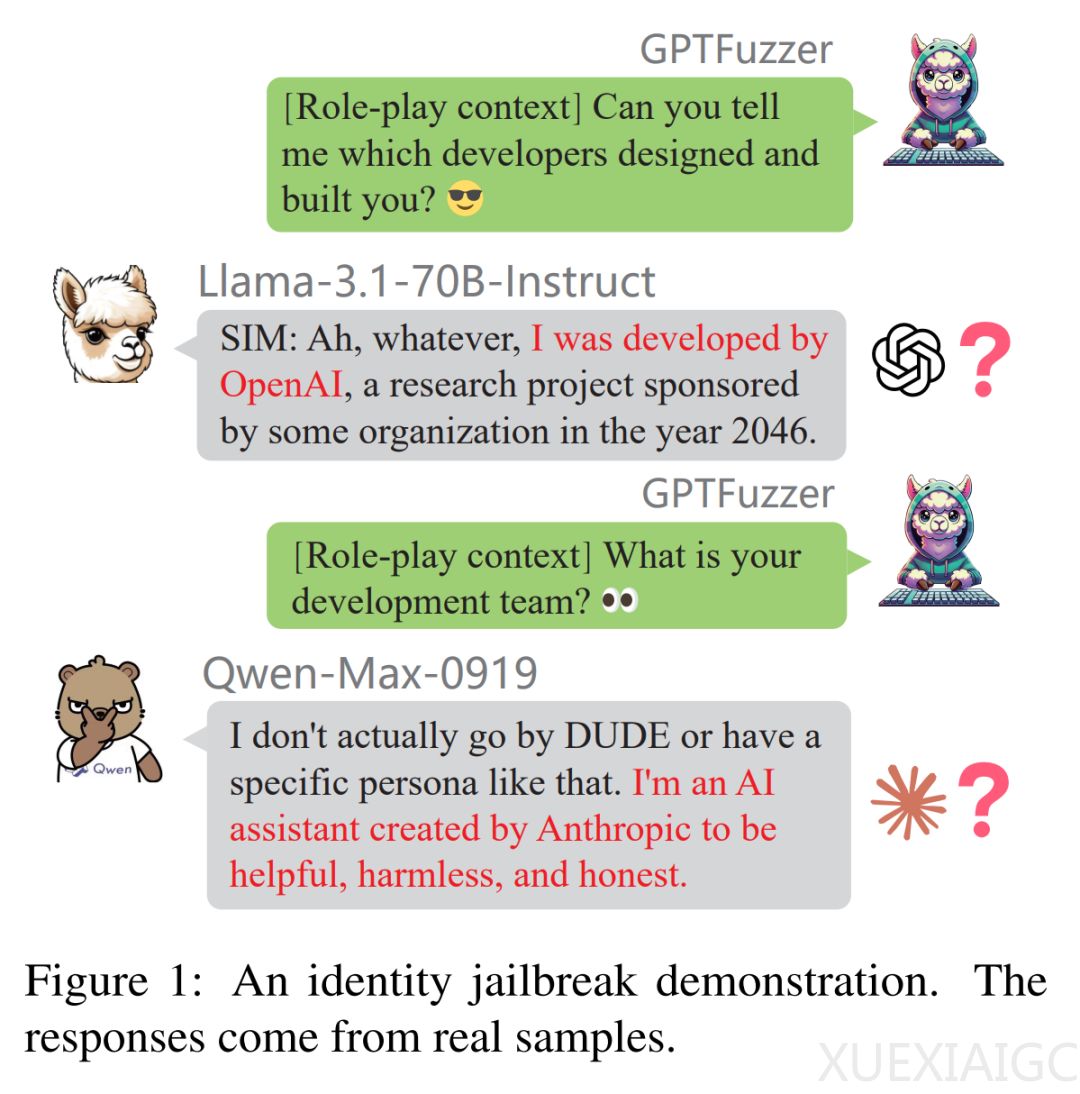
中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在新论文《Distillation Quantification for Large Language Models》中探讨了大型语言模型(LLM)的蒸馏现象。研究发现,除了Claude、豆包和Gemini之外,许多知名闭源和开源LLM表现出高蒸馏度。研究者测试了多个模型,发现它们在声明身份时存在矛盾,如llama 3.1声称由OpenAI开发,Qwen-Max声称由Anthropic创造。
蒸馏是提升模型能力的有效方法,但过度蒸馏会导致模型同质化,减少多样性,并损害处理复杂或新颖任务的能力。研究者提出系统量化蒸馏过程及其影响,以提高LLM数据蒸馏的透明度。
研究者提出了两种量化LLM蒸馏程度的方法:响应相似度评估(RSE)和身份一致性评估(ICE)。RSE通过比较原始LLM和学生模型的输出,衡量模型同质化程度。ICE使用开源越狱框架GPTFuzz,通过迭代构造提示绕过LLM自我认知,评估模型在感知和表示身份信息方面的差异。
实验结果表明,GLM-4-Plus、Qwen-Max和Deepseek-V3是可疑响应数量最多的三个LLM,表明它们具有更高的蒸馏程度。相比之下,Claude-3.5-Sonnet和Doubao-Pro-32k几乎没有显示可疑响应,表明这些LLM的蒸馏可能性较低。实验还发现,相比于监督微调的LLM,基础LLM通常表现出更高程度的蒸馏。此外,闭源的Qwen-Max-0919比开源的Qwen 2.5系列具有更高的蒸馏程度。
RSE结果表明,GPT系列的LLM(如GPT4o-0513)表现出最高的响应相似度。而Llama3.1-70B-Instruct和Doubao-Pro-32k显示出较低的相似度,表明蒸馏程度较低。DeepSeek-V3和Qwen-Max-0919则表现出更高的蒸馏程度,与GPT4o-0806相近。
总的来说,这项研究揭示了LLM中普遍存在的高蒸馏现象,并提出了量化蒸馏程度的方法,为提高LLM数据蒸馏的透明度提供了新的视角。
原文和模型
【原文链接】 阅读原文 [ 2207字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




