文章摘要
林达华是一位深度学习与计算机专家,他在大模型领域取得了重要突破。
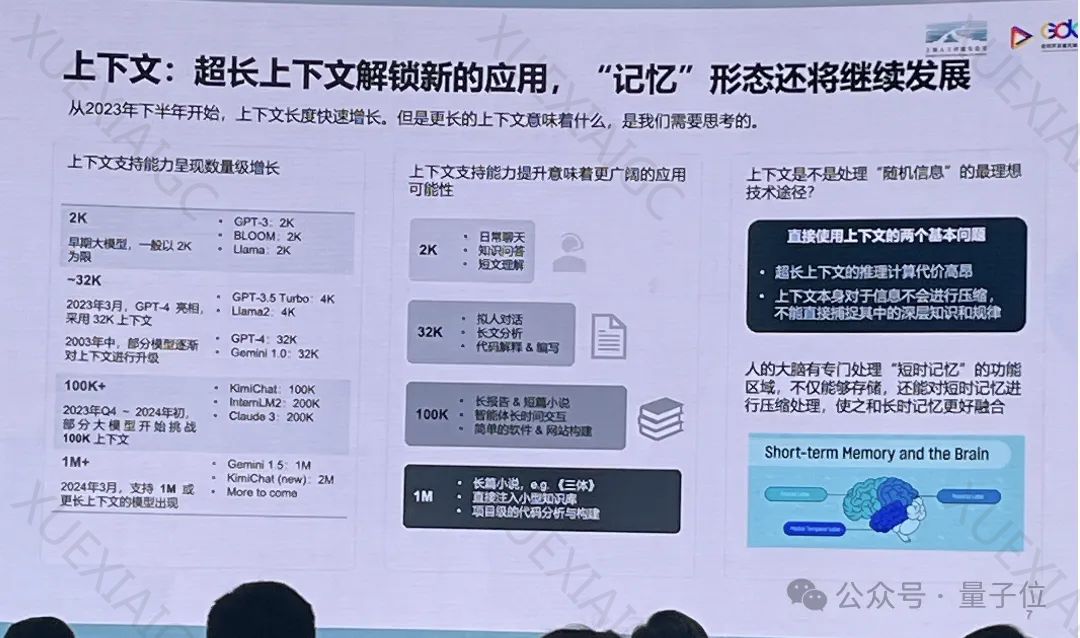
他指出,大模型的关键在于能够将海量信息串接起来做出深层次的结论,这远比简单的检索问题复杂。
在大模型的发展方向上,林达华强调了评估超长文本能力的计算代价的重要性,认为要考虑性价比是否最理想。
他总结了大模型赛道的四点现状:OpenAI引领技术潮流,Google紧随其后,Claude异军突起;技术探索的重点方向包括上下文、推理能力和更高效的模型架构;轻量级模型崭露头角;开源模型快速发展,开放生态已成气候。
林达华认为,大模型时代的技术演进主要受到对AGI的追求和对产业变革的憧憬的驱动。
在模型架构方面,业界开始从追求参数转向追求更高效的规模,MoE等架构备受关注。在训练数据方面,业界也在从追求数量转向寻求规模化构建高质量数据,强调数据的质量对模型水平的重要影响。多模态融合被认为是未来的重要技术趋势,但仍需探索。智能体的发展需要建立在坚实的基础模型上,具备指令跟随、理解、反思和执行能力。计算环境方面,端侧算力即将迎来黄金增长期,云端协同将成为未来重要趋势。国内大模型在主客观表现上超过了GPT-3.5,但与GPT-4的差距在于推理能力。林达华认为,国内大模型的优势在于应用场景非常丰富,但同时也强调了提升创新能力和原创水平的重要性。
原文和模型
【原文链接】 阅读原文 [ 1964字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-3.5-turbo-0125
【摘要评分】 ★★★★★

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



