从GPT-2到gpt-oss,深度详解OpenAI开放模型的进化之路
文章摘要
【关 键 词】 gpt-oss、Qwen3、模型架构、技术变革、模型比较
OpenAI 近日发布的 gpt – oss – 120b 和 gpt – oss – 20b 是自 2019 年 GPT – 2 发布以来的首批开放权重模型,Sebastian Raschka 对其进行了详细分析并与 Qwen 3 比较。
1. 模型架构概述:gpt – oss 模型乍看无新颖之处,领先的 LLM 开发商倾向使用相同基础架构并做小调整。原因可能是人员流动、未找到比 Transformer 更好的架构、改进多来自数据和算法调整。gpt – oss – 20b 可在 16GB RAM 消费级 GPU 运行,gpt – oss – 120b 可在 80GB RAM 或更高配置的单块 H100 处理器运行。
2. 自 GPT – 2 以来的变化
– 移除 Dropout:Dropout 是传统防过拟合技术,现代 LLM 多放弃,研究证实其在单轮训练方案中会致下游性能下降。
– RoPE 取代绝对位置嵌入:RoPE 通过旋转编码位置,已成为现代 LLM 主要组成部分。
– Swish/SwiGLU 取代 GELU:Swish 计算成本略低,前向模块被门控的「GLU」取代,可减少参数数量且性能更好。
– 混合专家取代单个前向模块:混合专家模型(MoE)增加模型总参数,但推理时仅使用部分专家,可积累知识且保证推理高效。
– 分组查询注意力取代多头注意力:GQA 分组共享键和值投影,减少内存占用和计算总量,不显著影响建模性能。
– 滑动窗口注意力:gpt – oss 每隔一层应用,可降低内存和计算成本,对建模性能影响小,GPT – 3 也曾使用。
– RMSNorm 替换 LayerNorm:RMSNorm 计算成本更低,更适合大规模 LLM。
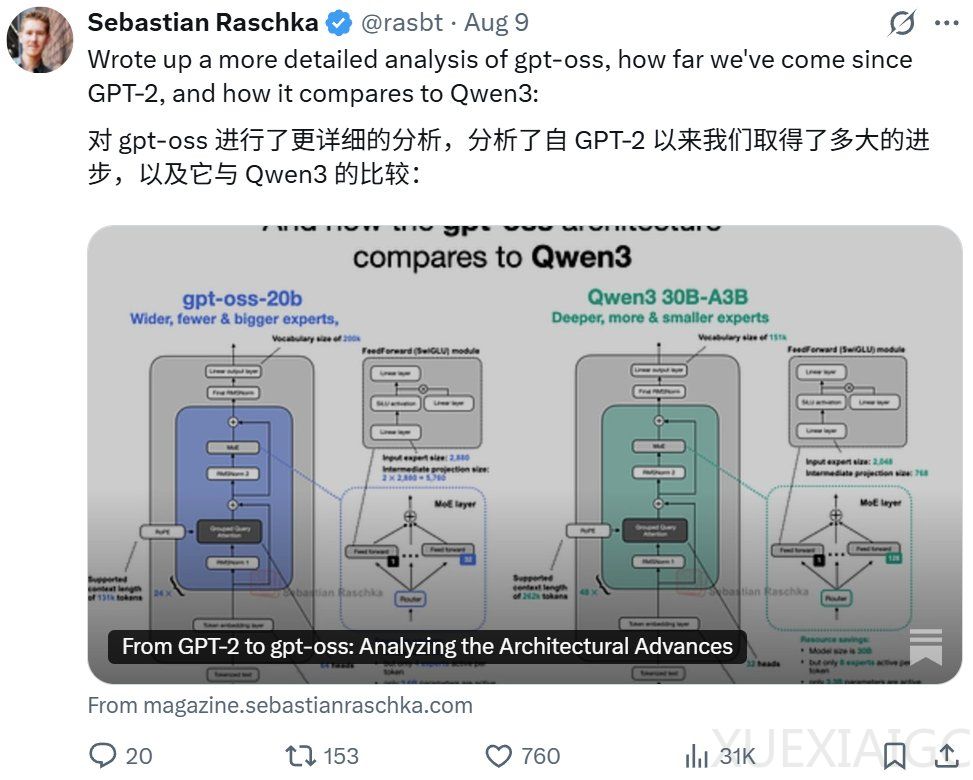
3. 与 Qwen3 比较
– 宽度与深度:Qwen3 架构更深,gpt – oss 更宽。更深模型灵活但训练难,更宽模型推理快但内存成本高。
– 少量大型专家 vs. 大量小型专家:gpt – oss 专家数量少但单个专家参数多,可能是 20B 规模副作用。
– 注意力偏差和 sinks:gpt – oss 使用偏差单元,通常被认为多余;注意力 sinks 是学习到的每人偏差逻辑单元。
– 许可证:gpt – oss 采用 Apache 2.0 开源许可证,是开放权重模型。
4. 其他有趣细节:gpt – oss 训练计算量约 210 万个 H100 GPU 小时数,用户可通过推理时间缩放控制推理程度。
原文和模型
【原文链接】 阅读原文 [ 7468字 | 30分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★☆☆☆☆


相关文章




