从未见过现实世界数据,MIT在虚拟环境中训练出机器狗,照样能跑酷
文章摘要
【关 键 词】 机器人学习、数据稀缺、模拟训练、图像生成、物理仿真
机器人学习领域面临的主要挑战之一是数据稀缺,尤其是与图片和文字数据相比。为了解决这一问题,MIT CSAIL的研究团队提出了一种新方法,即利用生成模型作为机器人学习的新数据源,以工程手段取代传统的数据收集。这种方法的核心在于通过生成模型加持的物理仿真来训练机器人视觉,从而实现机器人技能的提升。
在机器人训练过程中,随着技能的进化,所需的数据量也在增长。获取足够的数据对于提升机器人性能至关重要。然而,在当前实践中,针对新场景和新任务获取数据是一个从头开始不断重复的手动过程。另一种替代方法是在模拟环境中训练,这样可以对更多样化的环境条件进行采样,并且机器人可以安全地探索故障案例并直接从它们自己的行为中学习。
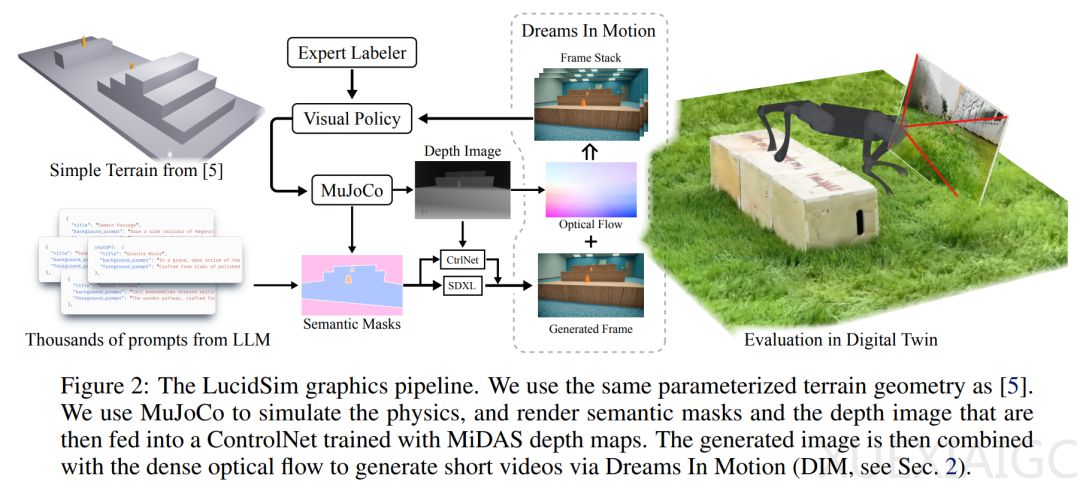
MIT CSAIL的研究者开发出了一套解决方案,他们将生成模型作为机器人学习的新数据源,并使用视觉跑酷作为试验场景,让配备单色相机的机器狗快速攀爬障碍物。研究者的愿景是完全在生成的虚拟世界中训练机器人,而核心在于找到精确控制语义组成和场景外观的方法,以对齐模拟物理世界,同时保持对于实现sim-to-real泛化至关重要的随机性。
研究者提出了一种名为Prior-Assisted Domain Generation(PADG)的方法,依赖生成模型内部的先验知识来填补信息空白。他们使用自动提示技术,从LLM中获取多样化、结构化的提示来源。为了获得多样化的图像,他们首先使用了包含标题块、查询详情的「元」提示,以提示ChatGPT生成批量结构化的图像块。
在几何和物理引导下生成图像,研究者增强了一个原始文本到图像模型,在增加额外语义和几何控制的同时,使它与模拟物理保持一致。他们采用了现成的ControlNet,该模型使用来自MiDAS的单目深度估计进行训练。为了制作短视频,研究者开发了Dreams In Motion(DIM)技术,它根据场景几何计算出的真值光流以及两帧之间机器人相机视角的变化,将生成图像扭曲成后续帧。
训练过程分为两个阶段:一是预训练阶段,通过模拟有权直接访问高度图的特权专家来引导视觉策略;二是后训练阶段,从视觉策略本身收集on-policy数据,并与当前收集的所有数据的学习交错进行。研究者遵循DAgger,将on-policy rollout与上一步中的教师rollout相结合。
实验结果表明,LucidSim在几乎所有评估中都优于经典域随机化方法。LucidSim能够识别经典的黑白足球,并且由于之前看到了具有丰富多样性的生成数据,因而可以泛化到不同颜色的足球。对于跨越障碍和爬楼梯场景,LucidSim能够始终如一地预测前方的障碍物并成功跨越。研究者还比较了基于on-policy的学习与原始的专家数据收集方法,结果显示,通过额外专家专用数据训练获得的性能增益很快达到饱和。在跨越障碍和爬楼梯场景中,通过DAgger进行on-policy学习对于制定足够稳健的策略很有必要。
原文和模型
【原文链接】 阅读原文 [ 3491字 | 14分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



