作者信息
【原文作者】 前端玩转AGI
【作者简介】 旨在分享对技术的理解,包括不限于大模型,Agents、前端框架(vue/angluar)、跨端框架(Ionic、Capacitor、Electron)、工程化(webpack/vite)、分享最前沿的国内外技术文章,做技术流的搬运工
【微 信 号】 gh_48d79173f38d
文章摘要
【关 键 词】 大语言模型、应用前景、ChatGPT、应用场景、基础知识
文章总结:
本文主要介绍了大语言模型(Large Language Model,LLM)及其在2023年及以后的应用前景。作者认为,2023年将成为大语言模型应用的元年,并将推动人工智能及IT产业进入新时代。
大语言模型是一种基于Transformer架构的大规模神经网络程序,主要用于理解和处理各种语言文字。这种模型具有通用学习的能力,无需对特定语言文字进行大量定制。
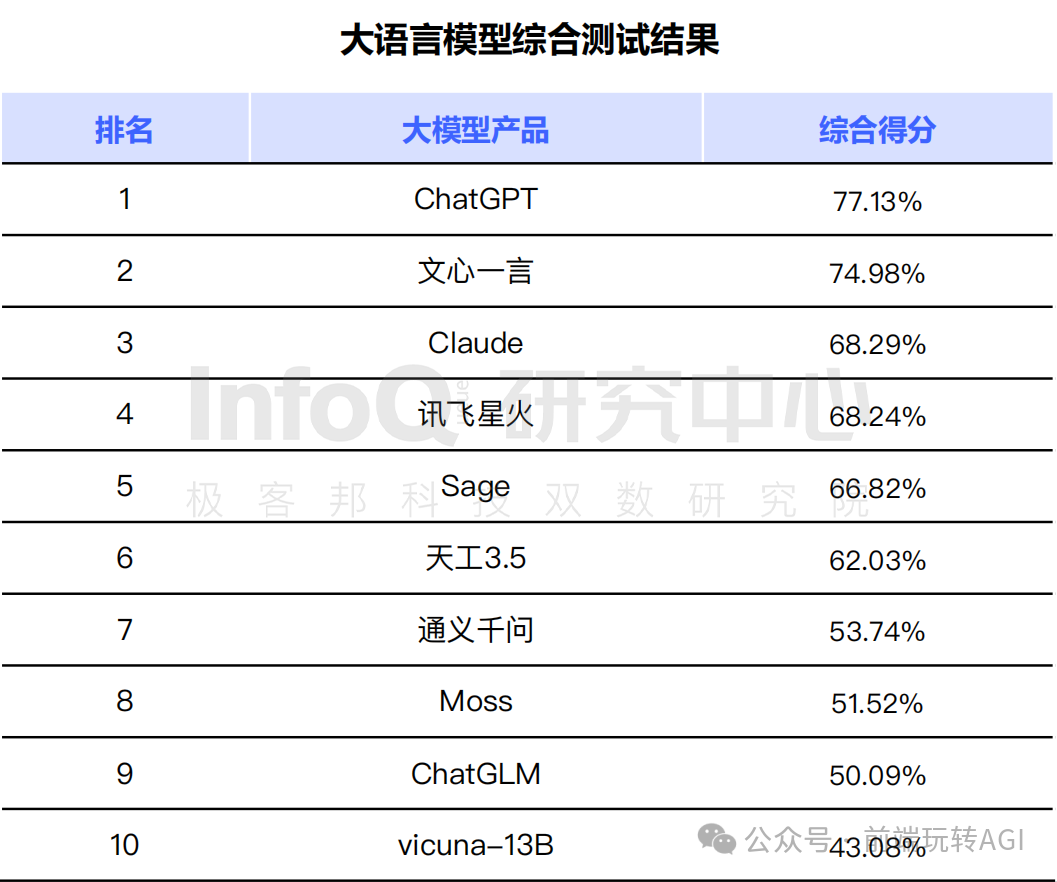
文章提到了OpenAI发布的基于GPT模型的聊天机器人ChatGPT,以及全球主流的其他大语言模型,如Anthropic的Claude2模型、Meta的LLaMA2开源模型和Google的PaLM2模型。InfoQ研究中心发布的《大语言模型综合能力测评报告2023》对这些模型进行了综合评测。
大语言模型的应用场景非常广泛,包括智能对话、文本生成、知识问答、文本总结、文本翻译、情感分析、数据分析、编程辅助、文档格式转换和信息抽取等。
文章还介绍了大语言模型的一些基础知识,如Token、提示词(prompt)、上下文长度和AI幻觉等。最后,作者区分了模型和产品,并解释了如何理解开源大模型名字上的参数。
原文信息
【原文链接】 阅读原文
【原文字数】 5032
【阅读时长】 17分钟
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...




