文章摘要
【关 键 词】 多模态模型、数据泄露、评估基准、MMStar、性能测试
近期,中科大、香港中文大学和上海AI Lab的研究团队发现了一个有趣的现象:即使没有查看图片,一些大型语言模型和多模态模型也能在多模态基准测试MMMU中取得不错的成绩。这一发现引发了对当前多模态模型评估方法的质疑。
研究人员指出,造成这种现象的两个主要问题是:一些多模态评估样本缺少对视觉内容的依赖性,以及现有评估过程未考虑语言和多模态大模型训练过程中的数据泄露问题。例如,一些问题的答案可以从题目和选项中直接推断出来,或者可以通过模型内嵌的世界知识来解答,而不需要依赖图片信息。此外,由于多模态评估样本往往是从单模态文本语料中转化而来,如果大语言模型的训练数据中包含了这些样本,就可能导致数据泄露,影响模型间的公平比较。
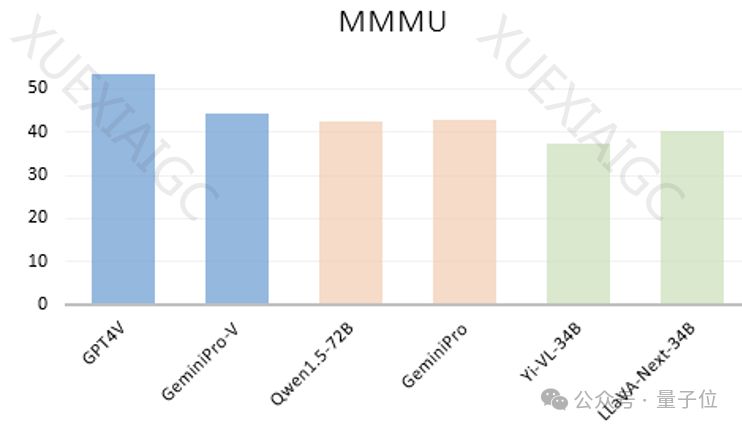
为了验证这一现象,研究者们对22个大语言模型在6个公开benchmark上进行了评估。结果显示,即使在没有图片的情况下,闭源模型GeminiPro和开源模型Qwen1.5-72B也能在MMMU基准上取得接近多模态模型的成绩。此外,他们还发现,经过多模态训练的模型在没有图片输入的情况下,其性能提升远大于在有图片输入的情况下。
为了进行更公平和准确的评估,研究者们设计了一个新的多模态评估基准MMStar,包含了1,500个具有视觉依赖性的高质量评估样本,并提出了两个新的评估指标:多模态增益(MG)和多模态泄露(ML)。在MMStar基准上的测试结果显示,大多数大语言模型的表现接近随机选择,表明MMStar中的数据泄露较少。在评估16个多模态模型时,没有一个模型能够在所有维度上及格,尽管GPT4V在高分辨率设置下取得了最高的平均性能。
研究团队认为,MMStar基准和相应的评估指标对于社区检验新开发的多模态benchmarks将是有益的。相关的论文、项目和代码已经公开,供研究社区进一步探索和验证。
原文和模型
【原文链接】 阅读原文 [ 1379字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-4
【摘要评分】 ★★★☆☆


相关文章


