模型信息
【模型公司】 OpenAI
【模型名称】 gpt-3.5-turbo-0125
【摘要评分】 ★★★☆☆
文章摘要
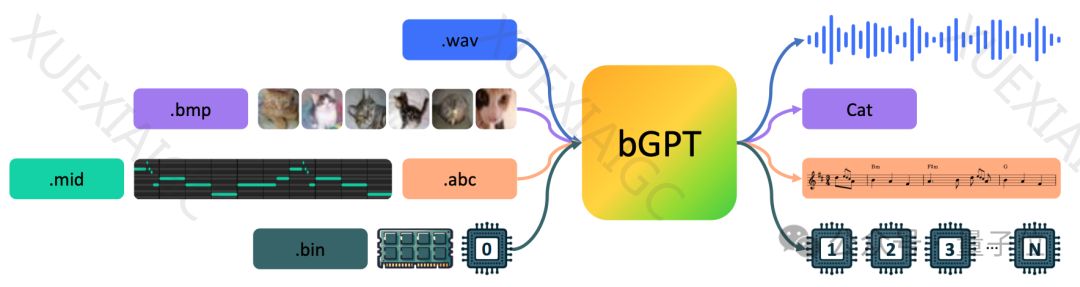
文章介绍了微软亚洲研究院等机构发布的新型GPT模型bGPT,该模型不再预测token,而是基于Transformer模型预测下一个字节。bGPT通过处理原生二进制数据,将所有输入内容视为字节序列,从而不受限于特定格式或任务,能够预测CPU行为和模拟MIDI音乐格式,准确率超过99.99%。研究团队认为传统深度学习忽视了字节,而字节构成了数字世界的基础。bGPT展示了处理原生二进制数据的能力和可扩展性,同时也展示了在生成/分类任务上的潜力。bGPT采用了字节到块的转化方法,提高了数据处理效率和处理长序列数据的简便性。虽然bGPT存在局限性,如只能处理不超过8KB的数据序列,但未来的研究将专注于提高算法效率和降低计算成本,以拓宽其应用范围。文章还探讨了bGPT在推动人工智能进步方面的潜力,包括实现通用人工智能和将AI作为操作系统的概念。最后,文章提到bGPT的代码和模型已开源,鼓励对字节级模型感兴趣的人尝试在自己的数据集上使用bGPT进行训练。
原文信息
【原文链接】 阅读原文
【阅读预估】 1945 / 8分钟
【原文作者】 量子位
【作者简介】 追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...




