文章摘要
【关 键 词】 自我博弈、强化学习、多模态、推理能力、大语言模型
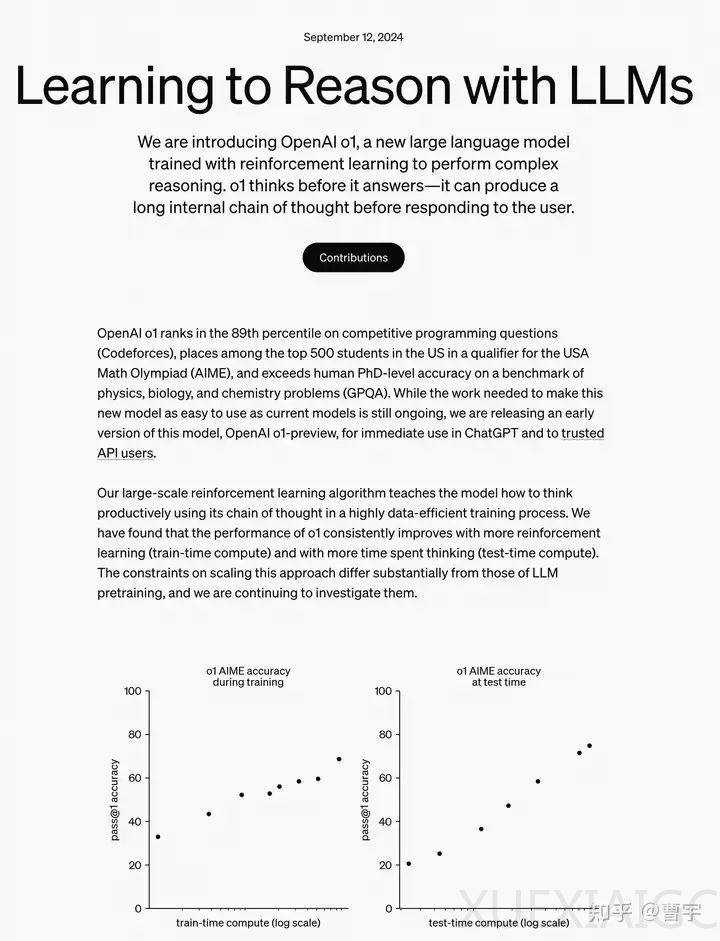
曹宇在其文章中深入分析了OpenAI的新型自我博弈强化学习(RL)模型o1,该模型在数理推理领域取得了显著成绩,并提出了训练时计算(train-time compute)和测试时计算(test-time compute)两个新的RL扩展法则。o1模型是一个多模态模型,其低调发布并未引起广泛关注,但其在多模态框架中的表现突出,得分高达78.1分。o1模型的命名暗示了其技术路线可能与GPT-4系列有所不同,代表了一种全新的模型pipeline。
o1模型的性能提升得益于在训练时的强化学习以及推理时的深入思考。这表明在特定领域,后训练(post train)的收益依然存在,但需要超越简单的监督学习(SFT)和训练时的扩展。o1模型展示了在没有人类参与的情况下,通过提出假设、验证思路和反思过程,实现逻辑推理能力。
文章中提到了“草莓”模型的梗,它源于GPT系列在处理“草莓”单词中字母“r”数量的问题上的失败。o1模型通过自我博弈提升了其推理能力,能够正确解码加密信息,展示了其在推理过程中的逐步思考能力。
曹宇进一步探讨了大语言模型(LLM)的扩展法则,特别是self-play LLM的挑战与机遇。他指出,为了使self-play有效,生成器(Generator)和验证器(Verifier)都必须足够强大。随着奖励数据的增加和奖励模型(RM)的强化,self-play的基础正在得到加强。新的扩展趋势表明,生成式RM能够提供更准确的评估,并且能够与大语言模型进行更深入的互动。
文章还讨论了test-time推理的scaling模式,包括Best of N搜索和深度推理scaling。这些模式展示了self-play RL在推理时的不同可能性,以及如何通过给模型更多的计算预算来提升准确度。
最后,曹宇推演了o1可能的技术路线,包括self-play actor-critic RL和self-play RL与自我验证器的结合。这些路线强调了在没有人类监督信号的情况下,通过搜索和记忆的组合来提升模型性能。他总结说,o1模型是一个早期预览版本,它突破了传统的训练和推理模式,预示着大语言模型在各个领域通过self-play实现突破的确定性技术方向。尽管o1目前看起来像是一个领域模型,但随着领域的扩展,我们可能会看到更强大的模型,如o1和o2,再次展现RL的力量。
原文和模型
【原文链接】 阅读原文 [ 5645字 | 23分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


