《Python机器学习》作者科普长文:从头构建类GPT文本分类器,代码开源
文章摘要
【关 键 词】 文本分类、模型微调、语言模型、性能评估、改进方向
在Sebastian Raschka的长文中,他详细阐述了如何将预训练的大型语言模型(LLM)转化为文本分类器。文章首先强调了文本分类在商业应用中的重要性,如垃圾邮件检测、情感分析等,并提出了七个关键问题,这些问题涉及模型微调的各个方面。
文章介绍了两种常见的语言模型微调方法:指令微调和分类微调。指令微调是针对特定任务训练模型,而分类微调则是训练模型识别特定类别标签。尽管分类微调的模型只能判断类别,但它们在开发上更为简单。
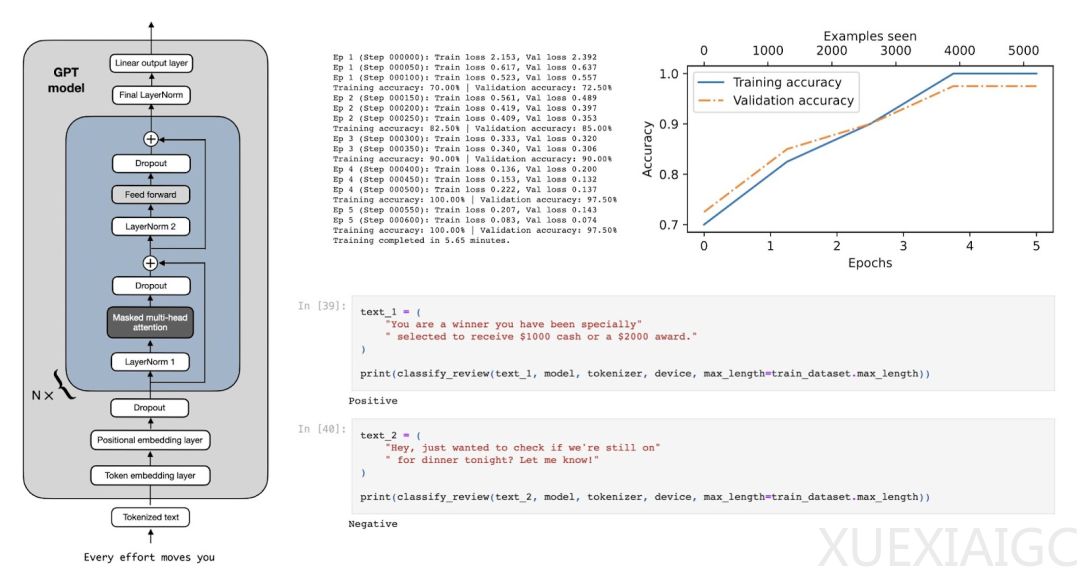
Raschka解释了如何使用预训练权重初始化模型,并展示了如何通过修改模型架构来适配分类任务。他指出,不需要对所有层进行微调,因为较低层的语言结构和语义是通用的。微调最后几层(靠近输出的层)就足够了,这些层更具体于任务特征。
文章通过代码示例展示了如何替换原始输出层,以适应二元分类任务,如垃圾邮件检测。作者还讨论了为什么选择最后一个token进行微调,这是因为在GPT模型中,最后一个token积累了最多的信息。
在评估模型性能方面,Raschka展示了训练和验证准确率的图表,显示出模型在训练过程中的表现。他还分享了一些补充实验的结果,这些实验探讨了是否需要训练所有层,以及为什么微调最后一个token而不是第一个token。
文章还比较了BERT和GPT在性能上的差异。尽管BERT在垃圾邮件分类任务上的表现略优于GPT-2,但两者在更大的数据集上的表现相似。这表明,在分类任务上,编码器风格的BERT和解码器风格的GPT模型之间没有显著差异。
最后,Raschka提出了一些可能的改进方向,包括禁用因果掩码以提升解码器风格模型的分类性能。他还提供了相关论文的链接,供读者进一步探索。
整体而言,这篇文章为那些希望了解如何将预训练的LLM转化为文本分类器的研究人员和开发人员提供了宝贵的指导和见解。
原文和模型
【原文链接】 阅读原文 [ 5098字 | 21分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




