文章摘要
【关 键 词】 GPT-4、图像生成、自回归模型、多模态、自动驾驶
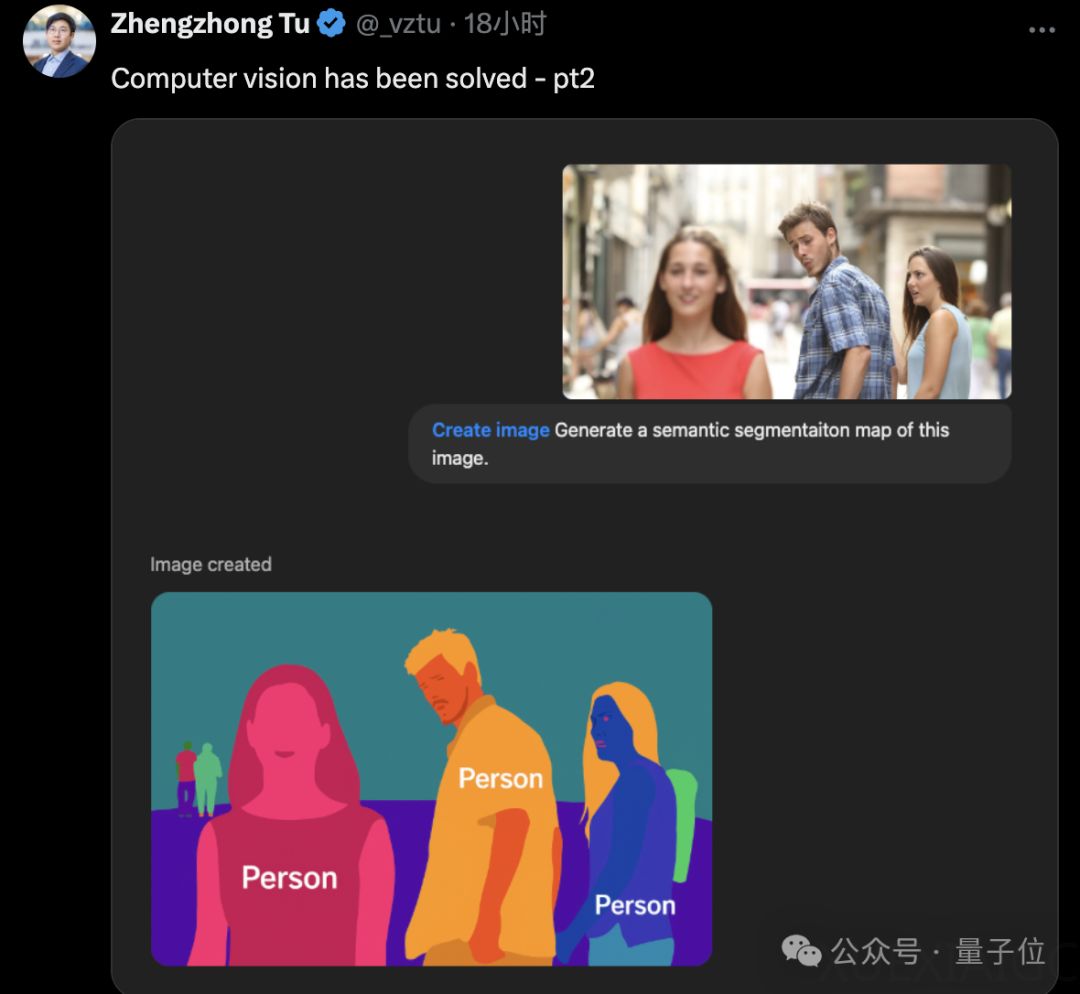
GPT-4o原生多模态图像生成技术的出现,标志着计算机视觉领域的一次重大突破。该技术不仅能够生成高质量的图像,还具备语义分割、深度图生成等复杂功能,甚至能够处理3D渲染中的PBR材质、纹理和法线贴图。这些能力的实现,使得传统的AI画图工具和设计师面临巨大挑战,同时也让计算机视觉研究员感到压力。OpenAI应用研究主管Boris Power甚至将这一技术应用于自动驾驶领域,认为只需训练最强大的基础模型并进行微调,即可实现自动驾驶系统的优化。
尽管有人认为这些功能可以通过Stable Diffusion和ControlNet等现有技术实现,但GPT-4o的独特之处在于其通过扩大基础模型规模来实现这些功能,这一方式令人意想不到。GPT-4o的图像生成技术被揭示为自回归模型,与DALL·E的扩散模型不同,它原生嵌入在ChatGPT内,能够根据之前的像素或patch预测下一个像素或patch,从而更好地遵循指令并具备图像编辑能力。此外,有观察指出,GPT-4o的图像生成过程可能是多尺度自回归的组合,先生成粗略图像,再逐步填充细节。
然而,关于GPT-4o的具体实现细节,OpenAI并未公开太多信息。有研究者从System Card中发现了一些线索,并推测在解码阶段可能仍然使用了扩散模型。Meta等机构在2024年8月发表的一篇论文提出了使用多模态模型同时预测下一个token和扩散图像的方法,这一研究为GPT-4o的实现提供了可能的参考。
总的来说,GPT-4o原生多模态图像生成技术的出现,不仅展示了AI在图像生成领域的强大能力,也为自动驾驶、3D渲染等多个领域带来了新的可能性。随着技术的进一步发展,GPT-4o的应用场景和影响力有望进一步扩大。
原文和模型
【原文链接】 阅读原文 [ 582字 | 3分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★☆☆☆☆


相关文章




