文章摘要
【关 键 词】 AIGC、大语言模型、数据集、指令微调、中文优化
随着人工智能的快速发展,大语言模型(LLM)在多个领域的应用变得越来越广泛。专注于AIGC领域的专业社区特别关注了微软 & OpenAI、百度文心一言、讯飞星火等大语言模型的发展和应用落地。这些模型的市场研究和开发者生态是该社区的关注重点。
近期,中国科学院、北京大学、中国科技大学、滑铁卢大学以及01.ai等十家机构联合推出了一个专门针对中文的高质量指令调优数据集——COIG-CQIA。这一数据集的推出,旨在解决中英文结构和文化差异导致的直接翻译英文数据集到中文的不足,填补高质量中文数据集的空白。
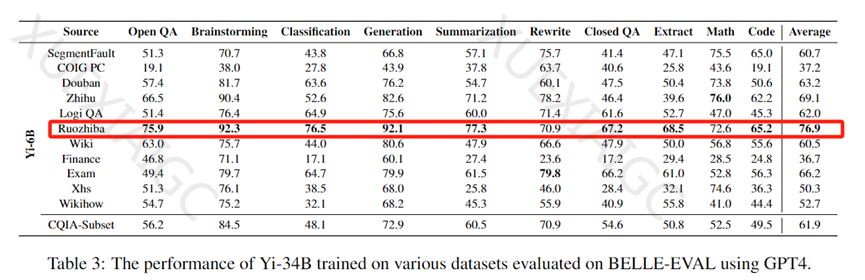
COIG-CQIA数据集包含了来自中文互联网论坛、网站、百度贴吧、问答社区等的高质量数据。研究人员使用这个数据集对Yi-6B、Yi-34B等模型进行了指令调优,并使用GPT-4在BELLE-EVAL上评估了在各种数据集上训练的大模型性能。结果显示,一些被认为数据质量较低的社区,如“弱智贴吧”,其数据质量意外地超过了知乎、豆瓣等知名知识社区。
COIG-CQIA数据集的构建涉及了22个高质量数据源,包括问答社区、百科网站、内容创作平台、考试题库等。研究人员根据不同社区的特点,采取了筛选高赞回答、评分过滤、人工审核等方式,确保数据的真实性和适用性。数据集还包括了广泛的概念解释和指导性文章,以及金融、电子、医学、农业等领域的专业知识。国内中学生、研究生的历年入学考试真题也被纳入数据集中,以提升模型的逻辑推理和知识综合能力。
在数据收集和分类整理之后,研究人员对每一类数据进行了深度清洗、重构和人工审查,以确保数据质量、多样性和对真实人机交互的贴合度。最终,构建了一个包含48,375条指令-输出对的高质量中文指令微调数据集。
指令微调是一种在大模型上进行微调的方法,它通过提供指令和输出来指导模型更准确地完成内容输出。这种方法类似于“妈妈教孩子”,按照特定格式帮助大模型更好地学习和输出拟人化内容。需要注意的是,指令微调和数据预训练是不同的,预训练让大模型学习通用知识,而不会针对任何特定领域进行数据微调。因此,高质量的指令微调数据集对于大模型的拟人化输出和内容的精准性至关重要。
通过对Yi系列、Qwen-72B等国内知名模型的微调测试,COIG-CQIA数据集显示出比现有开源中文数据集对大模型的帮助更为显著。这表明,高质量的中文数据集对于提升中文大模型的性能具有重要意义。
原文和模型
【原文链接】 阅读原文 [ 1235字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 gpt-4
【摘要评分】 ★★★☆☆


相关文章




