文章摘要
【关 键 词】 计算策略、模型优化、性能提升、硬件竞争、AI芯片
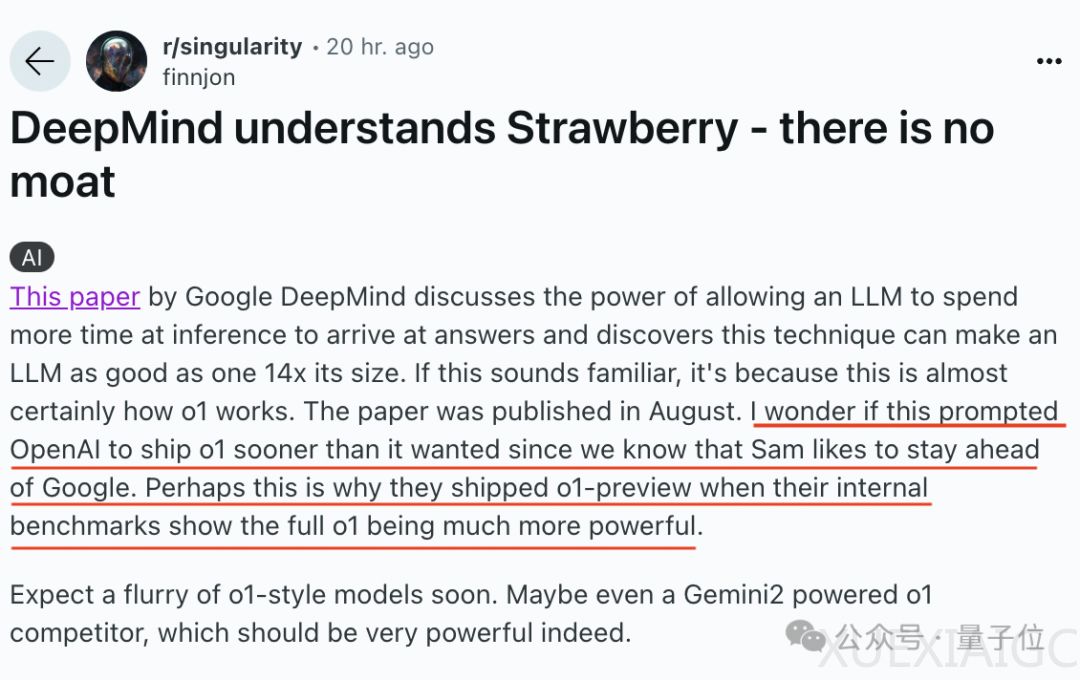
谷歌DeepMind的一篇论文揭示了一种新的计算策略,该策略与OpenAI的o1模型的工作方式几乎一致。这项研究指出,在测试时增加计算比扩展模型参数更有效,这使得较小的基础模型在某些任务上能够超越一个更大的模型。OpenAI随后提高了o1-mini的速度,并增加了使用频率。
论文的标题是“优化LLM测试时计算比扩大模型参数规模更高效”,研究团队从人类思考模式出发,探索了LLM在面对复杂任务时,是否可以通过增加测试时的额外计算来提高准确性。实验使用了PaLM2-S*模型在MATH数据集上进行,主要分析了迭代自我修订和搜索两种方法。结果显示,随着测试时计算量的增加,计算最优扩展策略与标准最佳N策略之间的差距扩大,且在某些情况下,计算量仅为后者的1/4。
研究还发现,使用自我修订方法时,当推理tokens远小于预训练tokens时,测试时计算策略的效果优于预训练。但在更难的问题上,预训练的效果更佳。此外,研究还比较了不同的PRM搜索方法,发现前向搜索需要更多的计算量。
OpenAI的o1模型通过完善思维过程、尝试不同策略和认识错误,随着更多的强化学习和测试时计算,性能持续提高。然而,谷歌的PaLM2尚未在Gemini2上更新。
网友评论指出,随着研究速度的加快,没有哪家公司能够确保始终领先,硬件可能成为唯一的竞争优势。英伟达控制着算力的分配,而谷歌/微软如果开发出更有效的定制芯片,可能会改变现状。OpenAI最近曝光的首颗芯片就是一个很好的例子,它将采用台积电的先进工艺,专为Sora视频应用设计。这表明,在大模型的竞争中,仅仅优化模型本身已经不够,硬件也变得越来越重要。
原文和模型
【原文链接】 阅读原文 [ 1121字 | 5分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章


