文章摘要
【关 键 词】 多模态、模型剪枝、计算优化、视觉注意力、性能保持
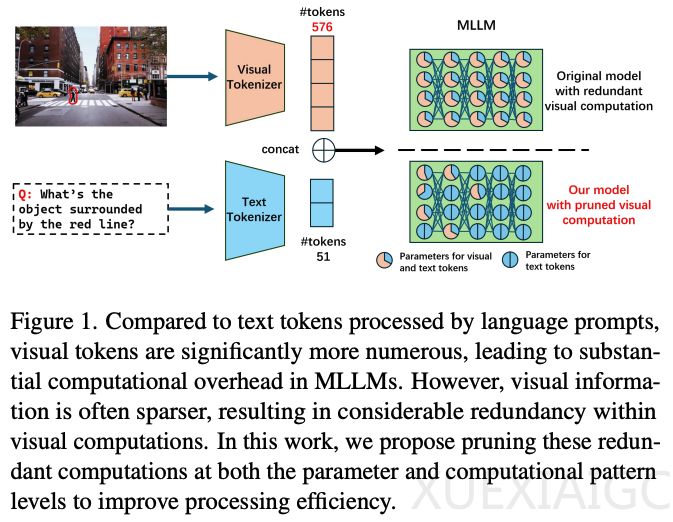
本研究由罗切斯特大学的张泽良博士生、徐辰良副教授以及Adobe的赵文天、万锟和李宇哲研究员共同完成,提出了一种针对多模态大模型的剪枝方法,旨在降低计算复杂度并保持模型性能。研究以LLaVA模型为实验对象,通过一系列剪枝策略,包括邻域感知的视觉注意力、非活跃注意力头剪枝、稀疏前馈网络投影和选择性丢弃视觉层,成功将计算量压缩至12%,同时保持了与原始模型同等的性能。这些策略在Qwen2-VL和InternVL2.0上也显示出普适性,验证了计算冗余性在多模态大模型中的普遍存在。
多模态大模型在跨模态任务中表现出色,但视觉token数量的快速增长导致计算复杂度呈二次方增长,限制了模型的可扩展性和部署效率。研究团队分析了视觉计算中的冗余性,并提出了高效的剪枝策略。实验结果表明,这些方法在显著降低计算开销(多达88%)的同时,保持了模型在多模态任务中的性能表现。
具体策略包括:
1. 邻域感知的视觉注意力:限制视觉token仅与其邻近token交互,降低注意力计算复杂度。
2. 非活跃注意头剪枝:剪枝未激活的注意力头,减少冗余计算。
3. 稀疏投影的前馈网络:在前馈网络隐藏层中随机丢弃神经元,利用视觉表达的稀疏性。
4. 选择性层丢弃:跳过靠后的层中与视觉相关的计算,减少计算开销。
实验结果表明,剪枝后的模型在四个基准任务上均表现最佳,超出第二名方法3.7%-2.2%。与其他剪枝方法相比,本方法在相同FLOPs下性能仅下降0.5%,证明了多模态大模型中视觉计算冗余的有效优化。此外,剪枝策略在其他多模态大模型上也显示出广泛适用性,即使不进行微调,性能也未受影响。
本研究为多模态大模型的高效计算提供了新的视角和解决方案,通过深入挖掘视觉参数和计算模式的冗余性,实现了在保持性能的同时显著降低计算复杂度的目标。
原文和模型
【原文链接】 阅读原文 [ 2217字 | 9分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


