Transformer死角,只需500步后训练,循环模型突破256k长度泛化极限
文章摘要
【关 键 词】 循环模型、长度泛化、训练干预、状态传递、有效记忆
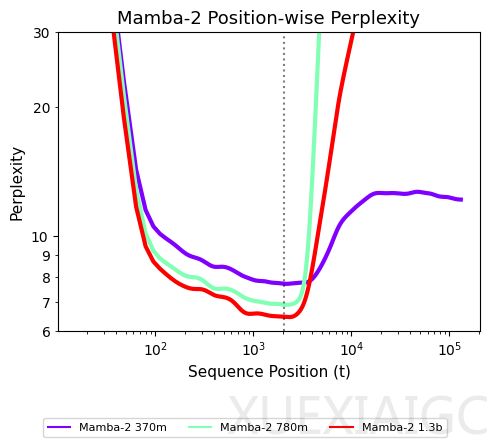
线性循环模型和线性注意力机制在处理极长序列方面展现出显著优势,这一能力对长上下文推理任务至关重要。与Transformer相比,这些模型突破了二次计算复杂度的限制,但过去在短序列任务中的性能不足限制了其应用。近期架构改进使循环模型性能显著提升,已能在音频建模和代码补全等工业场景中与Transformer媲美。然而,循环模型仍存在关键短板:在超出训练长度的序列上泛化能力明显下降,表现为困惑度指标急剧恶化。
研究发现,循环模型的状态分布随时间变化是导致长度泛化失败的根本原因。当序列位置超出训练范围时,模型会遇到未探索过的状态,无法产生正确输出。Mamba-2的状态范数随时间显著增长的现象证实了这一观点。基于此,研究者提出未探索状态假说,认为模型仅在有限状态子集上训练是泛化失败的本质原因。该假说指出,要实现长度泛化,必须让模型接触长序列状态递推产生的分布多样性。
通过四种训练干预方法可有效解决这一问题:随机噪声初始化、拟合噪声初始化、状态传递(SP)和截断时间反向传播(TBTT)。实验表明,仅需500步后训练(约占预训练预算0.1%),就能使模型在256k长度的序列上实现泛化。特别值得注意的是,状态传递和TBTT两种干预展现出最强的泛化能力。这些方法不仅能稳定状态范数,还能修正模型对远程token的过度依赖问题。
在具体任务验证中,状态传递显著提升了模型在BABILong基准测试中的表现,增强了常识理解和长程依赖捕捉能力。密码检索任务中,经过拟合噪声微调的780M参数模型能完美解决256k长度的序列任务。合成复制任务则证明,状态传递使模型能处理三倍于训练长度的序列。这些结果证实训练干预不仅能实现长度鲁棒性,还能真正解决需要长上下文推理的任务。
研究进一步提出有效记忆(EffRem)指标来量化模型对上下文的处理方式。未经干预的模型显示出对早期token的过度依赖,而状态传递干预后的模型则表现出更合理的记忆模式:优先考虑最近上下文,避免被远处token不必要干扰。这一发现为理解循环模型的工作机制提供了新视角,表明简单的训练干预就能显著优化其信息处理方式。
该研究打破了”循环模型存在根本缺陷”的认知,证明通过恰当的训练策略,循环模型具有尚未被充分释放的长序列处理潜力。这些发现不仅对改进现有模型架构具有指导意义,也为实现真正具有长记忆能力的实时智能系统开辟了新途径。
原文和模型
【原文链接】 阅读原文 [ 3538字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章




