文章摘要
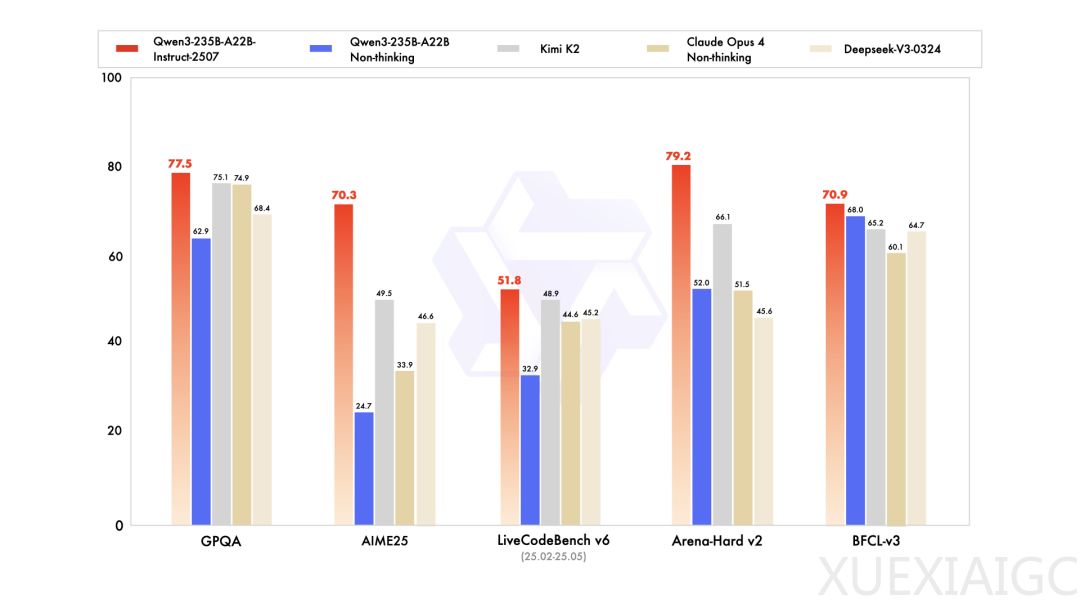
开源大模型领域近期迎来了显著的技术进展,尤其是中国市场的竞争愈发激烈。Kimi K2作为一款备受关注的模型,其1T的总参数量在短时间内被Qwen3的新版本超越。Qwen3-235B的总参数量仅为Kimi K2的四分之一,但在基准测试中表现更为优异,尤其是在数学推理能力上,AIME25的准确率从24.7%大幅提升至70.3%。这一突破不仅展示了Qwen3的技术实力,也进一步推动了开源大模型的竞争格局。
此次Qwen3的更新主要集中在架构和性能的优化上。新模型采用了因果语言模型架构,并引入了MoE(Mixture of Experts)机制,总参数量达到235B,其中非嵌入参数为234B,推理时激活参数为22B。模型共包含94层,采用分组查询注意力(GQA)机制,配备64个查询头和4个键值头,并设置128个专家,每次推理时激活8个专家。这种设计显著提升了模型的通用能力,包括指令遵循、逻辑推理、文本理解、数学、科学、编码和工具使用等方面。
新模型原生支持262144的上下文长度,增强了对256K长上下文的理解能力。这一改进使得模型在处理长文本任务时表现更为出色,尤其是在多语言长尾知识的覆盖范围上有了显著提升。此外,模型在主观和开放式任务中的表现也得到了优化,能够提供更有帮助的响应和更高质量的文本生成。这些改进不仅提升了用户体验,也为模型在实际应用中的表现奠定了坚实基础。
在与其他主流模型的对比中,Qwen3新版本的表现同样亮眼。无论是Kimi K2还是DeepSeek-V3,Qwen3在多个基准测试中都略胜一筹。这种技术优势使得Qwen在中等规模的语言模型中占据了领先地位,甚至有网友认为Qwen正在开启新的架构范式。
值得注意的是,Qwen官方还透露此次更新只是一个小更新,更大的技术突破即将到来。与此同时,NVIDIA也宣布发布了新的SOTA开源模型OpenReasoning-Nemotron,提供四个规模:1.5B、7B、14B和32B,并且可以实现100%本地运行。然而,这一模型实际上是基于Qwen-2.5在Deepseek R1数据上微调的产物,进一步凸显了Qwen在开源大模型领域的影响力。
随着Llama转向闭源的消息传出,OpenAI的开源计划迟迟未见进展,开源基础大模型的竞争正在进入中国时间。DeepSeek、Kimi K2和Qwen之间的激烈竞争不仅推动了技术的快速迭代,也为用户带来了更多选择和可能性。Qwen3的发布和后续预告的技术突破,无疑将进一步加剧这一领域的竞争态势。
原文和模型
【原文链接】 阅读原文 [ 703字 | 3分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★☆☆☆☆


相关文章



