模型信息
【模型公司】 OpenAI
【模型名称】 gpt-4-0125-preview
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 大型语言模型、Andrej Karpathy、OpenAI、技术解析、未来展望
在人工智能领域,大型语言模型(LLMs)已成为近两年的热门焦点,其背后的原理结合了简单直观与深刻智慧。Andrej Karpathy,OpenAI的创始人之一,以其对技术的深入解析而受到广泛尊敬。本文旨在探讨LLMs的奥秘,希望为读者提供帮助。
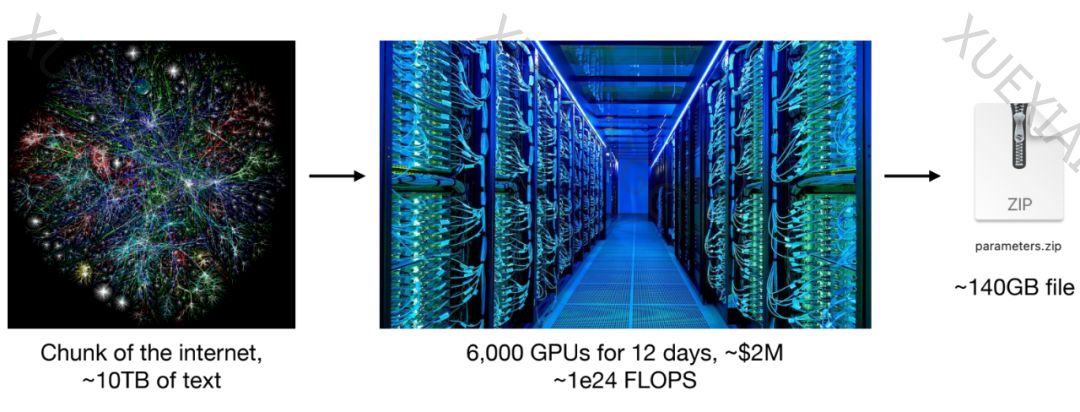
大型语言模型本质上由两个核心组件构成:一个包含亿万计权重的巨大参数文件,以及一个运行这些参数的代码文件。参数文件是模型的“DNA”,而代码文件则是其“大脑”,共同赋予了LLMs理解和生成文本的能力。例如,由meta开源的Llama2 70B模型,就是这样一个由参数文件和代码文件组成的系统,展现了LLMs的强大处理能力。
获取参数文件的过程,即模型训练阶段,是一种将海量互联网数据“压缩”到模型中的过程,需要巨大的计算资源。而模型的工作原理,基于一个核心任务:依靠神经网络对所给序列中的下一个单词进行预测。然而,在这一过程中,模型可能会遇到所谓的“幻觉”问题,即在缺乏确切信息的情况下,试图构建一个貌似合理的输出。
为了提升模型的性能,训练过程通常包括预训练、微调和标注偏好等阶段。预训练阶段处理TB级别的通用数据,微调阶段则通过较小但高质量的数据集进一步优化模型,最后通过人类评估反馈进行强化学习训练。
未来的LLMs将朝着多个方向发展,包括规模扩大、接入更多工具、多模态发展、深思熟虑的Tree of Thought、自优化能力、客户端定制化以及至关重要的安全性等。这些发展方向预示着LLMs将在教育、科研、商业等多个领域发挥更大作用,同时也面临着更复杂的安全挑战。
总之,大型语言模型正处于快速发展之中,其未来的潜力和价值令人期待,但同时也需要我们在安全性和伦理性方面给予足够的关注和努力。
原文信息
【原文链接】 阅读原文
【阅读预估】 5050 / 21分钟
【原文作者】 Tim在路上
【作者简介】 Spark、LakeHouse、大模型 欢迎关注知乎账号”Tim在路上”

相关文章





