文章摘要
【关 键 词】 强化微调、性能提升、领域专家、精确度高、专业知识
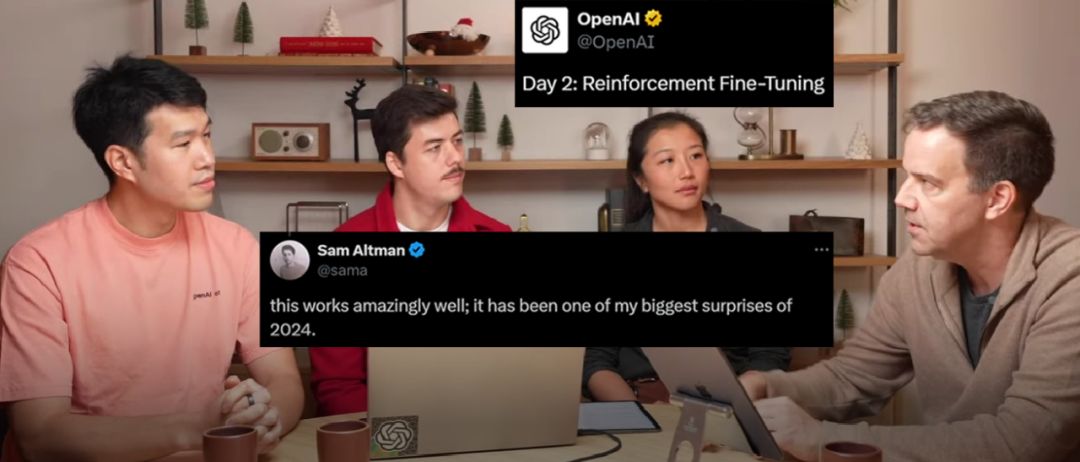
OpenAI在连续直播的第二天中展示了强化微调技术的强大能力,该技术使得o1-mini模型在性能上全面超越了基础模型o1。这是OpenAI首次将仅供内部使用的强化学习技术对外开放,允许开发者通过提供少量高质量任务来定制领域专家模型,并对模型的回应进行评分。强化微调不仅提升了模型在特定任务上的准确性,还增强了其在处理领域问题时的推理能力,对于需要高精确性和专业知识的领域尤为重要。
在官方演示中,经过强化微调的o1 mini在Top-1准确率上提升了180%,达到了31%,远超o1的25%。这一成果被奥特曼称为2024年最大的惊喜之一。强化微调研究计划目前已进入Alpha阶段,预计于2025年第一季度公开发布。
强化微调的技术思路与字节跳动团队在ACL 2024录用为Oral的论文中提出的ReFT(Reinforced Fine-Tuning)相似。ReFT通过在线强化学习(PPO算法)优化模型,自动采样大量推理路径,并根据真实答案获取奖励以微调模型。实验表明,ReFT在多个数据集上显著优于SFT(Supervised Fine-Tuning),并且具有卓越的泛化能力。
OpenAI的强化微调功能允许用户在自己的数据集上微调o1模型,利用强化学习算法将模型从高级中学水平提升到专家博士级别。这对于法律、金融、工程、保险等领域尤其有用。例如,OpenAI与汤森路透合作,利用强化微调使o1 Mini成为法律助手,完成了一些复杂、需要深入分析的工作流程。
伯克利实验室的Justin Reese介绍了强化微调在其研究中的帮助,特别是在使用计算方法理解罕见疾病背后的遗传原因方面。通过与OpenAI团队合作,他们训练了o1模型,使其更高效地推理疾病的成因,并在预测可能引发遗传疾病的基因任务上超越了o1。
OpenAI的Alpha计划将使更多人在最重要的任务上推动o1模型能力的边界,强化微调技术将在生物化学、AI安全、法律以及医疗保健等多个领域发挥作用。
原文和模型
【原文链接】 阅读原文 [ 2722字 | 11分钟 ]
【原文作者】 新智元
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




