文章摘要
【关 键 词】 作弊风波、模型对比、评估方法、开发者应用、OpenAI争议
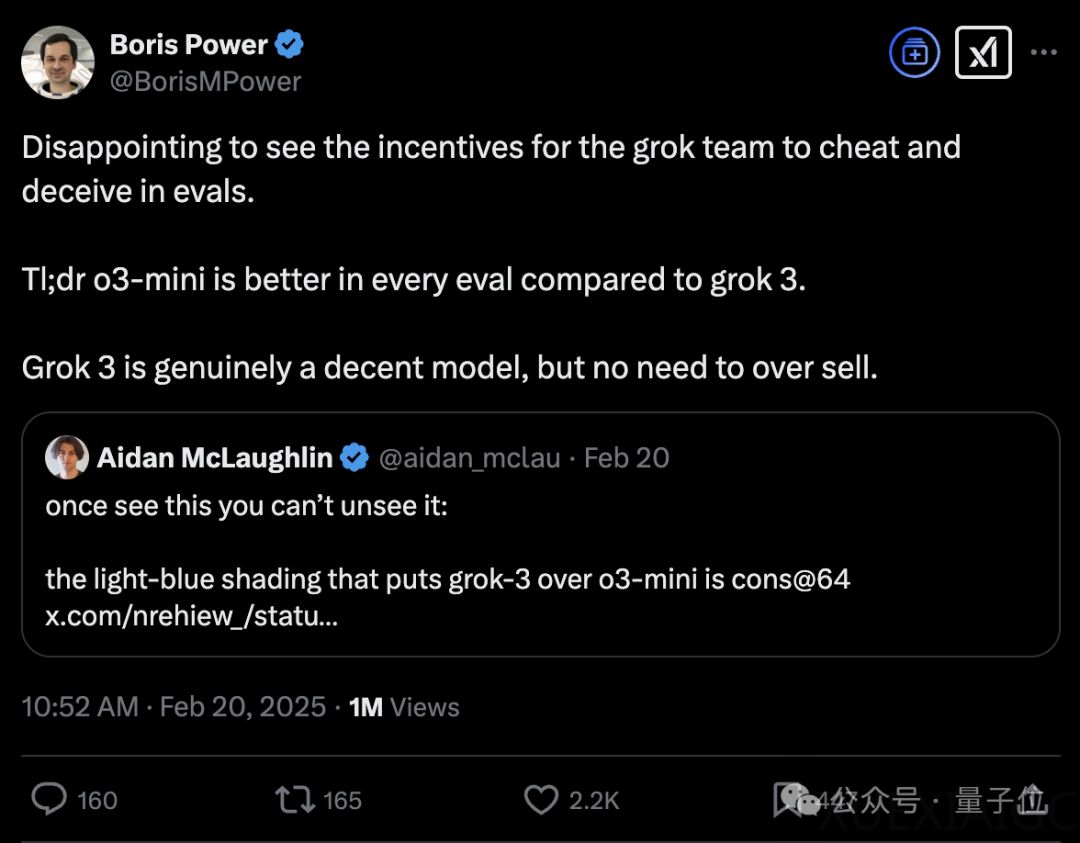
Grok-3模型发布后因评估方法引发争议,OpenAI团队公开指责其测试结果存在误导性。争议焦点集中在Grok-3的AIME 2025评估图中,其柱状图浅色部分标注为Con@64成绩——即模型通过生成64次答案后选取高频结果的方式获得,而对比模型如o3-mini、Gemini-2等并未采用相同测试方法。OpenAI应用主管指出,若统一采用单次回答评估,Grok-3实际表现仅与早期版本o1相当,两者技术差距可能长达9个月。
评估方法差异成为核心矛盾点。Con@64与pass@64存在本质区别:前者依赖多数投票机制,后者只需64次尝试中出现一次正确答案即可得分。OpenAI研究员Aidan McLaughlin强调,Grok团队将Con@64描述为”让模型花更多时间推理”,这种表述具有误导性,实际是计算策略而非认知能力的提升。数据显示,若o1模型采用Con@64,其表现甚至能与高配版o3-mini持平,凸显该方法对评估结果的显著影响。
争议双方均有历史渊源。OpenAI曾在o3-mini的测试中使用过类似对比形式,但此次未让o3-mini参与Con@64评估。部分业内人士认为,Grok团队可能在马斯克压力下选择有利于自身的对比方式,以缩短与行业领先者的表面差距。网友讨论指出,若严格统一测试标准,当前Grok-3的推理能力尚未达到顶尖水平。
尽管陷入争议,Grok-3的技术潜力仍受关注。该模型完成预训练仅一个月,通过思维链(CoT)后训练快速提升能力,且xAI正加速扩展算力基础设施。开发者社区已展现应用热情,成功利用Grok-3快速开发小游戏,例如在特斯拉车载系统实现彩色打砖块游戏,并通过自然语言指令调整游戏物理参数。马斯克近期成立AI游戏工作室的动向,进一步凸显其整合生成式AI与娱乐场景的战略布局。
技术社区对争议保持多元观点。部分声音认为评估标准不透明损害行业公信力,另一些则强调Grok-3在工程化落地和开发效率方面的突破价值。随着模型迭代加速,标准化评估体系的建立将成为避免类似争议的关键。
原文和模型
【原文链接】 阅读原文 [ 1102字 | 5分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-r1
【摘要评分】 ★★☆☆☆


相关文章



