文章摘要
【关 键 词】 推理架构、性能优化、分离式架构、自动运维、开源计划
在2024年QCon全球软件开发大会(上海站)上,月之暗面推理系统负责人何蔚然分享了“Mooncake分离式推理架构创新与实践”。何蔚然从实际业务出发,探讨了在固定集群资源下提升集群处理大规模请求的能力的挑战和解决思路。他介绍了Mooncake框架,从大规模推理挑战、单点性能优化、分离式架构和自动运维与故障定位四个维度进行了详细阐述。
何蔚然指出,面对长上下文处理的挑战,公司产品Kimi智能助手和Kimi开放平台依赖同一套推理引擎,每天产生数以万亿计的token量,要求处理能力极强。为了满足服务水平目标(SLO),集群长期满载,挑战在于不过载情况下优雅处理更多用户请求。为此,公司采取了特别的并行和调度策略,成本相比去年下降超20倍。
在推理降本价值观方面,公司坚信推理成本必然降低,但模型智能水平不能下降。主要路径有两个:提高算子计算速度和降低显存需求,或寻找性价比更高的硬件。何蔚然分享了几个关键公式,包括更低的推理成本等于更省的模型结构加更便宜的硬件,更便宜的Long Context等于更快的Attention计算加更小的KVCache,更便宜的Generation等于更大的Batch Size加更Decode友好的并行方式。
在超长上下文性能挑战方面,长上下文处理面临的挑战主要是Full Attention的时间复杂度问题和KV Cache占用显存限制并行度。何蔚然介绍了自动运维与故障定位的措施,包括推理实例快速切换、硬件巡检、释放空闲资源执行离线任务等。
在单点性能优化方面,何蔚然分享了混合并行策略,包括Tensor Parallelism、Pipeline Parallelism、Expert Parallelism、Context Parallelism (Ring/AllToAll)、Chunked Pipeline Parallelism和Data Parallelism (not LB)。他还介绍了长上下文推理优化的一系列工作,如Moonshot Sparse Attention、Cache Blend、Dynamic MoE、Speculative Decoding、Cascade Attention和Fine-Grained CUDA Graph。
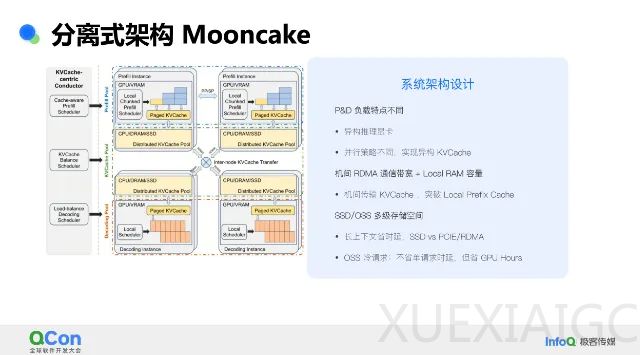
何蔚然重点讨论了分离式架构Mooncake推理系统的设计场景与系统收益。他指出,Prefill和Decode是两种不同负载场景,需要最大化吞吐量。通过优化,实现了TTFT的10倍提升、TBT的5倍提升和RPM的1.7倍提升。系统架构设计包含Prefill节点池、Decode节点池和虚拟的KV Cache池。
最后,何蔚然分享了典型场景分析,关键在于KVCache传输。他介绍了集群调度策略与热点均衡,包括Prefill&Decode节点动态平衡、热点均衡等。展望未来,何蔚然提到了开源计划,包括Trace Dataset和Mooncake Store,以及硬件能力的展望。
原文和模型
【原文链接】 阅读原文 [ 7316字 | 30分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



