文章摘要
【关 键 词】 Llama 3.2、量化模型、移动优化、性能提升、开源技术
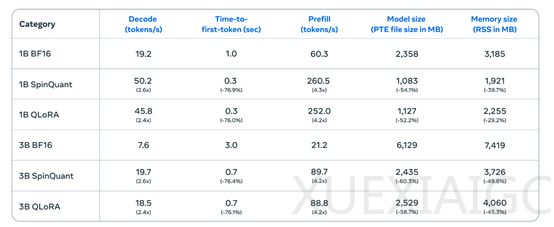
Meta公司最近开源了一款名为Llama 3.2的轻量级量化版大语言模型,提供10亿和30亿两种参数规模的版本。这款模型经过特别优化,以适应手机、平板和笔记本等移动设备。通过使用LoRA适配器的量化感知训练和SpinQuant技术,Llama 3.2在减少内存使用和模型规模的同时,推理效率提升了2到4倍。例如,在一加12手机上,解码延迟提高了2.5倍,预填充延迟提高了4.2倍。
Llama 3.2的架构基于标准的Transformer结构,对线性层进行了特定的量化处理,采用4位组方式量化权重,并对激活进行8位每标记动态量化。分类层则量化为8位每通道的权重和8位每标记的动态激活量化,同时使用了8位每通道量化用于嵌入。
模型优化方面,LoRA适配器量化感知训练和SpinQuant两种技术被用于提升性能。LoRA适配器量化在初始化量化感知训练时,使用经过有监督微调的BF16 Llama 3.2模型检查点,进行额外一轮带有量化感知训练的有监督微调训练。然后冻结量化感知训练模型的主干,再使用低秩自适应的LoRA适配器对所有层进行另一轮有监督微调。而SpinQuant则通过学习旋转矩阵来平滑数据中的异常值,促进更有效的量化。
Llama 3.2虽然参数规模较小,但支持128k tokens的上下文长度,这对于移动端处理长文本至关重要。Meta公布的测试数据显示,量化后的Llama 3.2在多个主流基准测试中性能并未减少,甚至能与Llama 3 8B的性能相媲美,展现了其高性能低消耗的特点。开源地址为:https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf。
原文和模型
【原文链接】 阅读原文 [ 853字 | 4分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★☆☆☆☆


相关文章


