模型信息
【模型公司】 OpenAI
【模型名称】 gpt-3.5-turbo-0125
【摘要评分】 ★★★☆☆
文章摘要
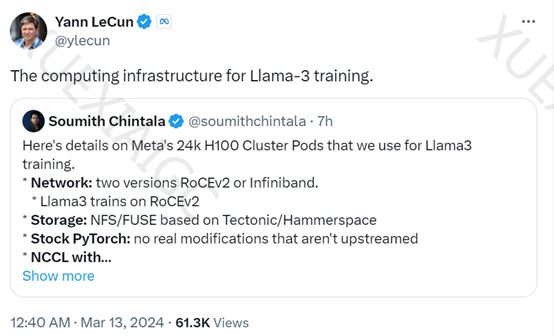
【关 键 词】 Meta、24K H100、Llama-3、PyTorch、AGI
3月13日,Meta宣布推出两个全新的24K H100 GPU集群,用于训练大型模型Llama-3。Llama-3采用RoCEv2网络和基于Tectonic/Hammerspace的NFS/FUSE网络存储,同时使用PyTorch机器学习库。预计Llama-3将于4月末或5月中旬上线,可能是一个多模态模型并将继续开源。Meta计划到2024年底拥有60万个H100算力。Meta一直致力于构建AGI(通用人工智能),并在2022年1月首次公布了拥有1.6万个英伟达A100 GPU的AI研究超级集群(RSC)。新的GPU集群建立在RSC的成功经验之上,每个集群包含24,576个H100 GPU,支持更复杂、参数更高的大型模型训练。Meta每天处理数百万亿次AI模型请求,因此使用高效、灵活的网络是确保数据中心安全稳定运行的关键。Meta已成功将RoCE和InfiniBand集群用于大型生成式AI工作负载,并没有出现网络瓶颈。新增的两个集群使用了Meta内部设计的Grand Teton GPU硬件平台,该平台于2022年10月首次发布,具有简化的设计、灵活性和易于维护和扩展等优点。数据存储方面,Meta的新集群使用了自创的用户空间Linux文件系统API来满足人工智能集群的数据和检查点需求,结合了Tectonic分布式存储解决方案和Hammerspace,实现了快速功能迭代。
原文信息
【原文链接】 阅读原文
【阅读预估】 1309 / 6分钟
【原文作者】 AI前线
【作者简介】 面向AI爱好者、开发者和科学家,提供大模型最新资讯、AI技术分享干货、一线业界实践案例,助你全面拥抱AIGC。

相关文章





