文章摘要
【关 键 词】 AI架构、Mamba-2、序列模型、性能优化、资源节省
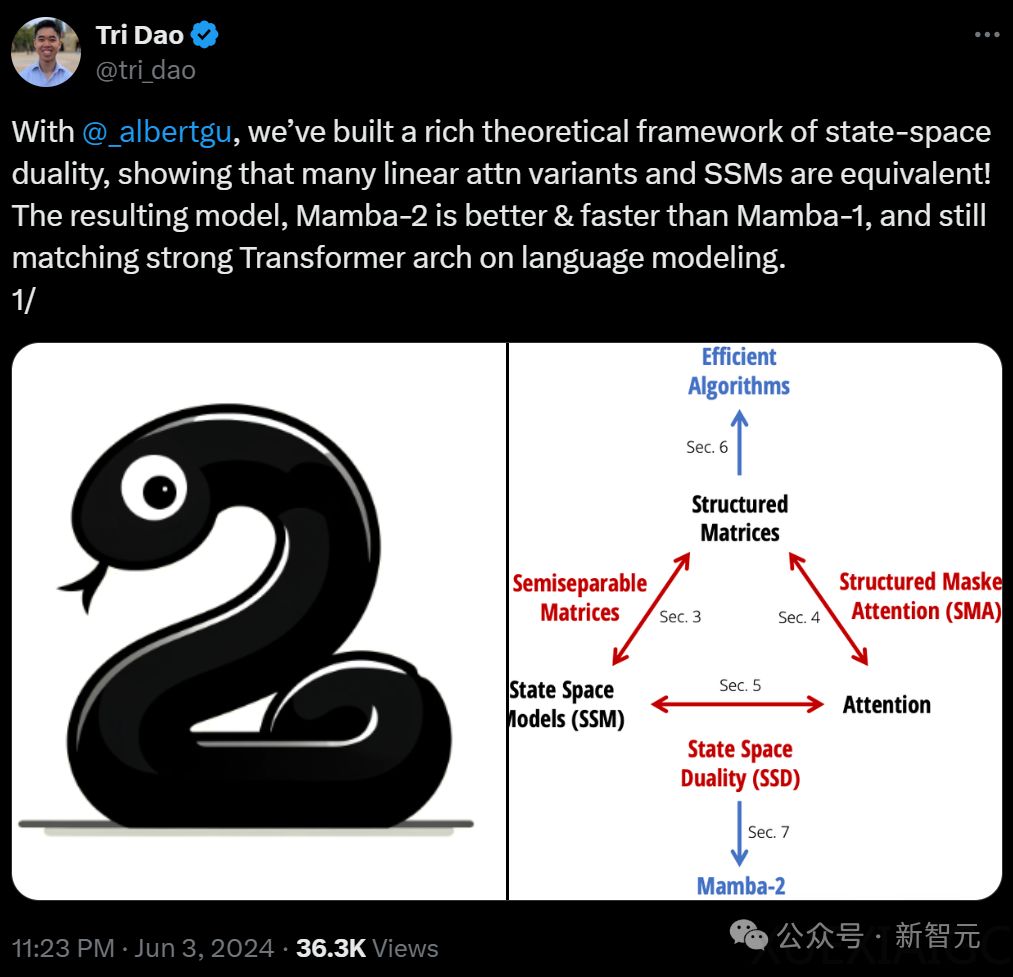
Mamba-2架构在AI界再次引发关注,其在统一状态空间模型(SSM)和注意力机制(Attention)的基础上,成功将Transformer模型与SSM结合,形成了一种新的高效序列模型。这种理论上的整合意味着在保持性能的同时,模型能更小、更省资源,并利用GPU硬件优化,大幅提升速度。
在Pile数据集上,使用300B token训练的Mamba-2-2.7B模型展现出优于其他大型模型如Mamba-2.8B、Pythia-2.8B甚至是Pythia-6.9B的性能。这一成果显示Mamba-2在模型大小与性能之间取得了新的平衡,并在AI社区中得到广泛的关注和研究,其前作Mamba在arxiv上的相关研究爆发性增长,学术引用量超过350。
Mamba的最初目标是为了解决当前AI社区在Transformer模型优化上的方向不一致问题。Mamba-2的成功意味着社区内针对Transformer的优化努力可以得到更好的利用,避免了资源的浪费。此外,Mamba-2的成功也意味着之前被ICLR拒稿的Mamba架构得到了肯定,其在ICML 2024的录取更是证明了其理论的深度和实用价值。
值得关注的是,与Mamba相关的其他研究,如Vision Mamba等,也成功入围ICML 2024,显示出这一新架构在AI领域的广泛影响力和应用潜力。这一系列进展预示着Mamba-2可能成为未来AI模型架构的重要趋势,引领序列模型研究的新方向。
原文和模型
【原文链接】 阅读原文 [ 7159字 | 29分钟 ]
【原文作者】 新智元
【摘要模型】 glm-4
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...


