Llama 4 详细评测:开源模型的全面倒退?
文章摘要
【关 键 词】 开源模型、性能对比、技术评估、价格分析、社区生态
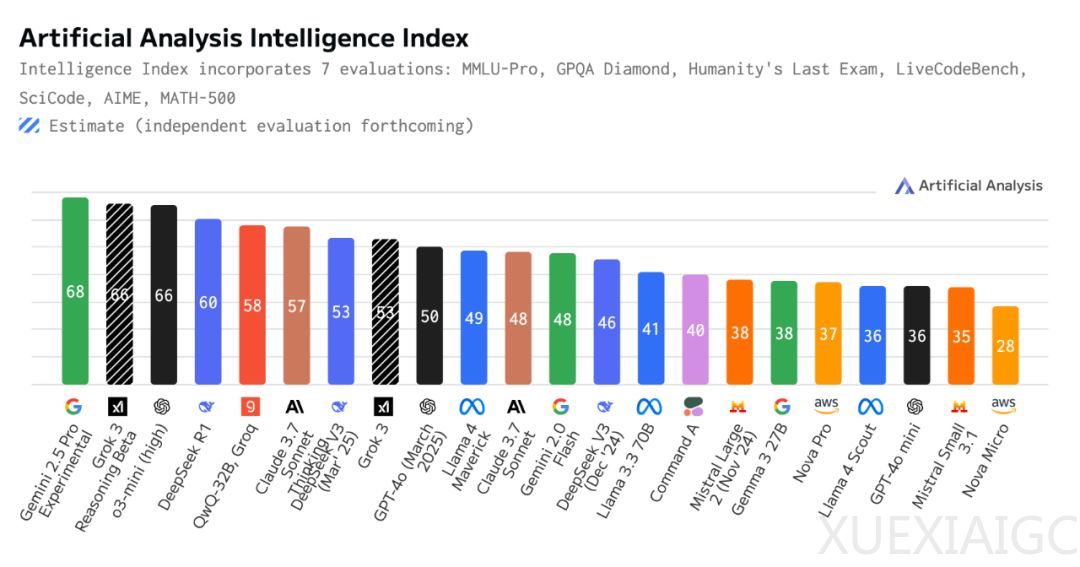
Meta最新发布的开源大模型Llama 4在技术社区引发了广泛争议。尽管其规格参数堪称“顶配开源”,包括两个混合专家(MoE)架构版本——Scout(109B总参数,17B活跃参数)和Maverick(400B总参数,17B活跃参数),并支持图文输入和1000万token的上下文窗口,但其实际表现却未能达到预期。根据Artificial Analysis的独立评估数据,Llama 4在多个关键任务中的表现与主流竞品存在显著差距。
在总体性能方面,Llama 4的表现令人失望。Maverick在Intelligence Index综合榜单中得分49,未能进入第一梯队,而Scout得分仅为36,甚至低于部分轻量模型。与Google的Gemini 2.5 Pro、xAI的Grok 3和DeepSeek R1等顶级模型相比,Llama 4的差距明显。特别是在非推理任务中,Maverick虽在开源模型中表现稳定,但与DeepSeek V3和GPT-4o等顶级模型相比,依然存在明显差距。Scout的表现则更为克制,虽不具备突破性优势,但在资源受限场景下仍具备一定实用价值。
在具体任务表现上,Llama 4的表现喜忧参半。在通用推理任务中,Maverick表现稳健,接近一线闭源模型,但Scout则明显吃力,整体排名不高。在科学推理任务中,Llama 4表现疲软,尤其是Maverick未能展现出预期能力,Scout的表现则更加堪忧。在编码能力方面,Maverick在基础编码任务中表现未达预期,Scout则在大部分编码任务中垫底,虽在高难度挑战中偶有亮点,但整体竞争力仍偏弱。在数学任务中,Llama 4两个版本表现出较为明显的分化,Maverick在基础数学任务中稳健发挥,但在竞赛级高难度数学任务中表现不佳,Scout也展现出一定的定量推理能力,但在复杂推理能力上存在短板。
在模型效率方面,Llama 4表现出一定的优势。Maverick的活跃参数约为DeepSeek V3的一半,总参数也仅为其60%左右,表明其以更高的效率实现了性能表现。此外,Maverick还支持图像输入,而DeepSeek V3则不具备这一功能。
在价格方面,Llama 4具有明显优势。Maverick的中位价格为每百万输入/输出token 0.24美元/0.77美元,Scout的定价为每百万输入/输出token 0.15美元/0.4美元,其价格不仅低于DeepSeek V3,相比OpenAI的GPT-4o接口更是便宜超过10倍。
尽管Llama 4在多个关键任务中的表现未能达到预期,但其多模态架构、超长上下文和低廉定价依然为未来铺路。开源的价值不仅在于性能指标,更在于长期可控性、社区生态与开放创新的累积潜力。Llama 4是否成为开源模型的全面倒退,还需看Meta和整个开源社区能否在质疑声中继续优化、快速迭代,将短板变成支点。真正的竞争,还远远没有结束。
原文和模型
【原文链接】 阅读原文 [ 2874字 | 12分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



