文章摘要
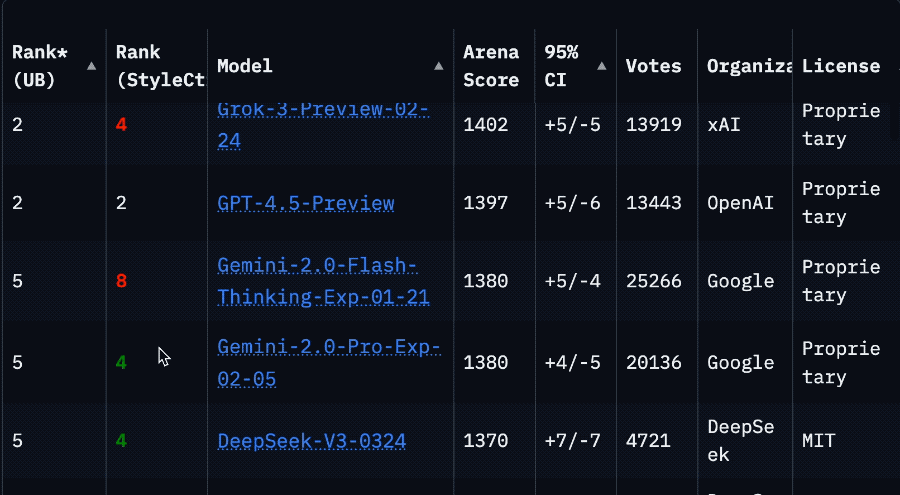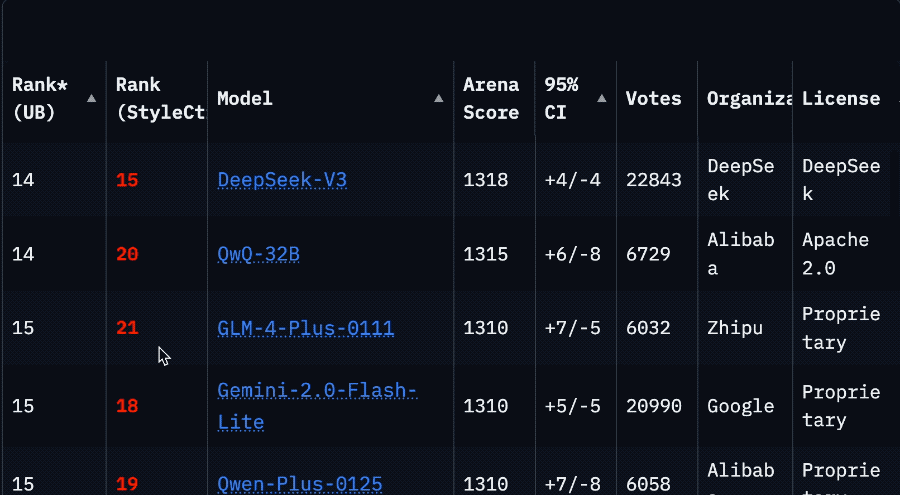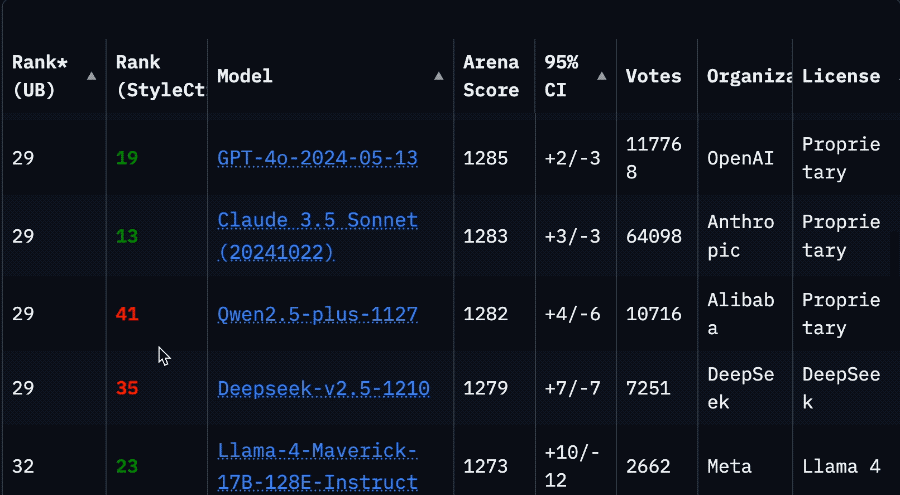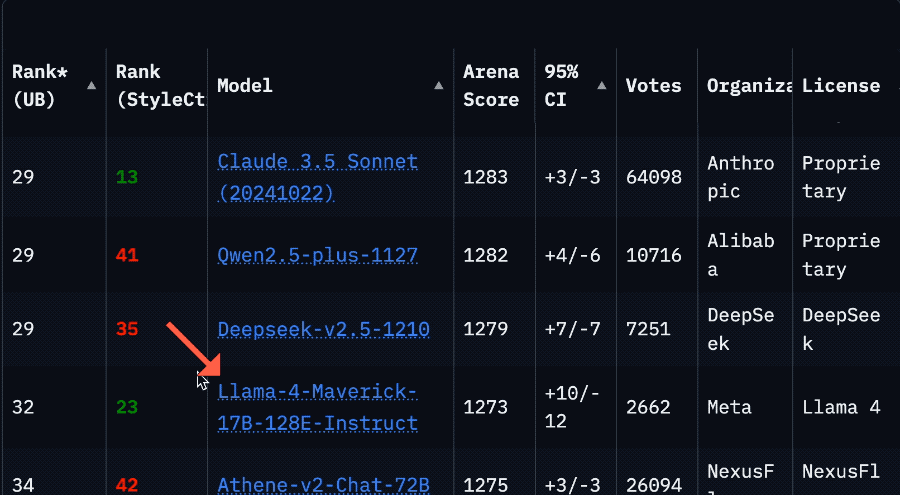
Llama 4模型在大模型竞技场中被曝作弊后,重新上架了非特供版模型,但其排名从第2位骤降至第32位。最初提交的“实验版”模型实际上是对人类偏好进行了优化,具体优化方式尚未公开。这一事件引发了社区对Meta的批评,认为其行为损害了信任。尽管如此,Llama 4模型在某些方面仍表现出色。开发者反馈显示,Llama 4在内存充足但计算能力较低的系统上表现优于Mistral Small 3.1,且在288GB内存双路至强服务器上运行速度较快。然而,对于游戏显卡或云API算力充足的环境,DeepSeek V3或闭源模型可能更具优势。
Agent创业公司Composio对Llama 4与DeepSeek V3进行了详细对比。结果显示,DeepSeek V3在代码能力和常识推理方面显著优于Llama 4。例如,在解决一道Leet Code题目时,DeepSeek V3通过了132个测试用例,而Llama 4仅通过10个。在常识推理任务中,DeepSeek V3不仅提供了正确答案,还展示了清晰的思维过程,而Llama 4则缺乏解释。然而,在大型RAG任务中,Llama 4表现出更快的执行速度,尽管在定位单词位置方面存在不足。
在写作任务中,两款模型均表现出色,但风格各异。Llama 4的写作风格更为细致,而DeepSeek V3则更为随意。在创作一个关于“删除”熟悉人物的故事时,DeepSeek V3的结局获得了高度评价,被认为悬念十足且令人印象深刻。总体而言,Llama 4在特定场景下具有优势,但DeepSeek V3在多项任务中展现了更强的能力。
原文和模型
【原文链接】 阅读原文 [ 1293字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★☆☆☆☆


相关文章




