作者信息
【原文作者】 努力犯错玩AI
【作者简介】 为AI开发者打造HuggingFace国内镜像站,提供最新流行开源模型资讯并免费加速下载。更多内容请访问https://aifasthub.com
【微 信 号】 gh_7709874d3358
文章摘要
【关 键 词】 LLaMA-VID、模型、技术方案、性能、应用场景
这篇文章主要介绍了LLaMA-VID模型,总结如下:
LLaMA-VID模型的主要目标是处理长时视频,并面临着挑战。为了解决这些挑战,采用了创新的方法。
该模型的技术方案包括采用了关键Token,并详细描述了其作用。
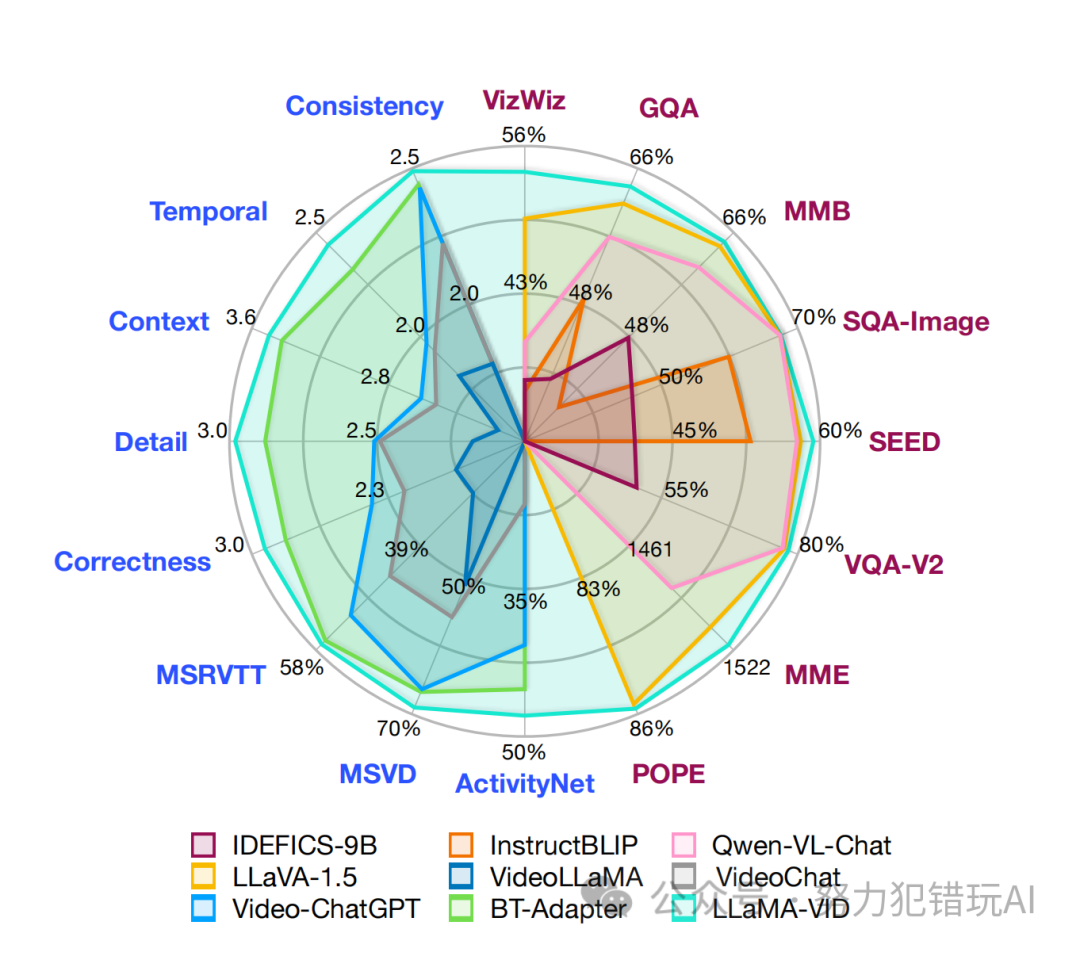
LLaMA-VID模型在处理长时视频方面表现出卓越性能,并在多个评估榜单上取得了成功。
该模型的应用场景包括电影制作、内容创作、娱乐分析和教育等领域。
最后一段总结了LLaMA-VID模型的重要意义,以及对AI领域的突破性贡献。
文章末尾提供了模型下载链接和往期好文推荐。
原文信息
【原文链接】 阅读原文
【原文字数】 1022
【阅读时长】 4分钟
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...




