LLM 比之前预想的更像人类,竟也能「三省吾身」
文章摘要
【关 键 词】 语言模型、自省能力、道德状态、自我预测、内省局限
近期,一个多机构联合团队的研究证实了语言模型(LLM)可以通过内省来了解自身。这项研究的论文标题为“Looking Inward: Language Models Can Learn About Themselves by Introspection”,提出了一个用于测量LLM自省能力的框架,包括新数据集、微调方法和评估方法,并给出了LLM具备自省能力的证据,同时说明了自省能力的局限性。
自省式模型能够根据其内部状态的属性回答有关自身的问题,即使这些答案无法从其训练数据中推断出来。这种能力可以用于创造诚实的模型,让它们能准确地报告其信念、世界模型、性格和目标,同时也能帮助人类了解模型的道德状态。然而,具备自省能力的模型也可能利用这一点来避开人类的监督。
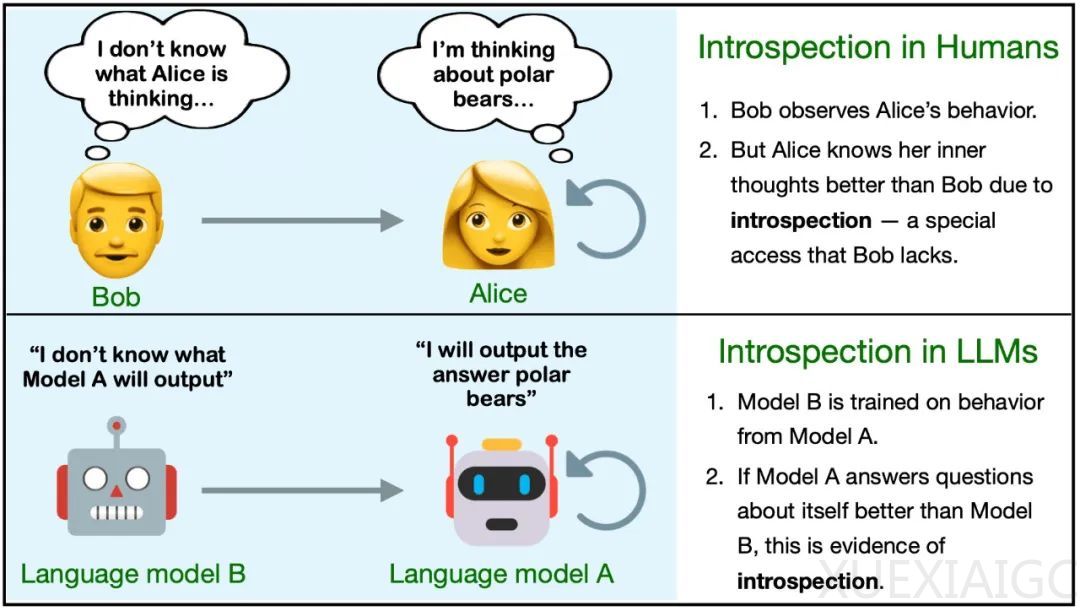
研究团队通过实验发现,LLM可以获得无法从其训练数据中推断出的知识,这种对关于自身的某些事实的“特权访问”与人类内省的某些方面有关联。他们定义了自省,并通过对模型M1和M2的不同行为进行比较,来说明M1通过自省得到的事实。
实验表明,模型在自我预测方面表现较弱,但通过微调可以显著改善。模型的自我预测性能取决于自省,自我预测模型的表现总是优于交叉预测的情况。此外,模型在自我预测时会进行校准,这表明模型考虑了其训练数据中没有的有关自身的信息。当自省式模型的对象级行为发生变化时,它应该有能力改变有关自身的预测结果,这也提供了支持自省的间接证据。
尽管如此,研究团队也指出,除了用自省来解释上述结果,也可能为其找到其它解释。他们进行了进一步的实验,展示了当前内省能力的局限性,包括无法预测涉及较长响应的属性、模型在预测自身行为方面没有优势的情况以及缺乏向其它自我知识数据集的泛化。
原文和模型
【原文链接】 阅读原文 [ 2579字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




