LLM仍然不能规划,刷屏的OpenAI o1远未达到饱和
文章摘要
【关 键 词】 o1模型、推理能力、规划能力、PlanBench、LLM
OpenAI最近发布的o1模型在通用推理能力方面取得了显著进展,但在规划能力方面仍有待提升。亚利桑那州立大学(ASU)的研究团队通过PlanBench基准测试评估了当前大型语言模型(LLM)的规划能力,包括o1模型。尽管o1在基准测试中性能超过竞争对手,但并未达到饱和状态。
在PlanBench基准测试中,即使是经过RLHF微调的Transformer模型也面临挑战,尤其是在Mystery Blocksworld测试中,没有一个LLM的准确率超过5%。这表明LLM本质上仍然是近似检索系统。测试还发现,自然语言提示比PDDL表现更好,且one-shot提示并非zero-shot的严格改进。
o1模型尝试通过结合底层LLM和RL训练系统来补充类似System 2的能力,但具体机制尚不清楚。在静态PlanBench测试集上,o1正确回答了97.8%的Blocksworld实例,但在Mystery Blocksworld上,准确率降至52.8%。这表明o1在规划任务上的性能仍然不够稳健。
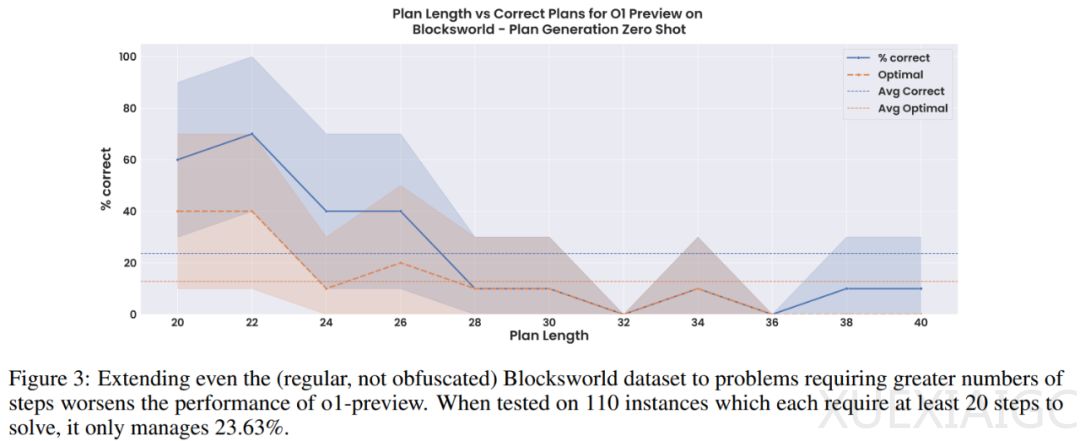
在更大的Blocksworld问题上,o1的性能迅速下降,准确率仅为23.63%。此外,在不可解决的实例上,o1仅正确识别了27%的实例为无法解决。在随机Mystery Blocksworld上,这些数字更糟,只有16%的案例被正确识别为无法解决。
研究团队还发现,o1-preview在每个问题使用的推理token数量方面受到限制,这可能限制了其整体准确性。如果o1的正式版本消除了这一限制,可能会提高准确性,但也可能导致推理成本不可预测。相比之下,o1-mini虽然成本较低,但性能通常较差。
总之,尽管o1模型在通用推理能力方面取得了显著进展,但在规划能力方面仍有待提升。LLM在规划任务上的表现仍然不够稳健,需要进一步的研究和开发。
原文和模型
【原文链接】 阅读原文 [ 1528字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章


