文章摘要
【关 键 词】 大模型竞争、Long CoT技术、强化学习、AGI趋势、模型优化
近期大模型领域呈现激烈竞争态势,DeepSeek R1与月之暗面Kimi 1.5推理模型相继展现技术突破。尽管Kimi团队通过通俗易懂的技术解析展示了其创新成果,但因未开源且传播受限,行业关注度相对不足。Long CoT技术的有效性在此次技术演进中被重新评估,其通过细粒度运算过程合成实现复杂问题求解的特性,虽在一年前已被验证,但受限于输出成本与速度,此前未成为优先发展路径。
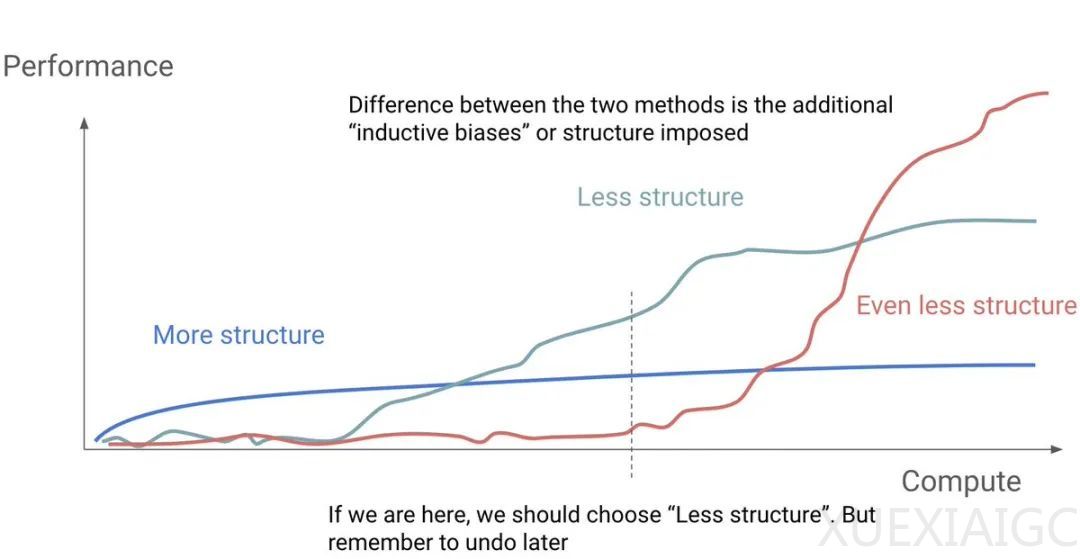
技术分析指出,Long CoT与传统结构化思维模式存在本质差异:允许模型在推理过程中反复试错、自主调整思考路径,且不预设固定框架。这种特性与OpenAI研究者提出的”Test-Time Search”理念高度契合,强调模型应具备自主搜索能力而非依赖人工预设结构。相关研究进一步揭示,结构化工作流仅具备短期价值,最终将被模型原生能力取代,这一结论对当前流行的Agentic Workflow技术路线提出挑战。
强化学习(RL)的应用策略成为关键突破点。研究团队通过分析o1模型案例发现,基于精确奖励机制的RL训练能有效提升模型性能,尤其在数学与编程等具有明确评估标准的领域。不同于传统RLHF对人工标注的依赖,新型训练方法将整个推理轨迹视为强化学习过程,通过自我批判机制实现动态优化。模型在训练中自主涌现出延长推理链条的能力,这一发现与DeepSeek的零样本强化学习成果形成技术呼应。
技术实现层面面临的核心挑战在于价值评估体系的构建。研究提出将复杂推理过程简化为上下文老虎机问题,采用改进型REINFORCE算法进行处理。只要最终结果正确,中间试错过程即被视为有效探索,该策略成功规避了传统奖励模型存在的价值评估偏差问题。实验数据显示,模型在性能提升过程中会自发增加推理步骤,印证了自主进化能力的可行性。
行业展望部分指出,AGI的实现路径已显现清晰轮廓:通过可量化的目标设定与强化学习相结合,模型可在复杂场景中持续进化。当前技术突破为自动驾驶、内容生成等现实应用奠定基础,而开源生态的竞争将进一步加速技术迭代。研究者预测模型自主能力将逐步覆盖结构化工作流,推动人工智能向更广义的任务解决方向演进。
原文和模型
【原文链接】 阅读原文 [ 2657字 | 11分钟 ]
【原文作者】 AI产品阿颖
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章




