文章摘要
【关 键 词】 AI模型、强化学习、多模态、开源许可、推理性能
近期,Kimi和DeepSeek两大AI研究机构分别发布了各自的最新模型:Kimi的k1.5和DeepSeek的DeepSeek-R1系列。Kimi 1.5在Github上发布技术报告,获得不到300 stars,而DeepSeek选择MIT许可开源,迅速获得3K stars。
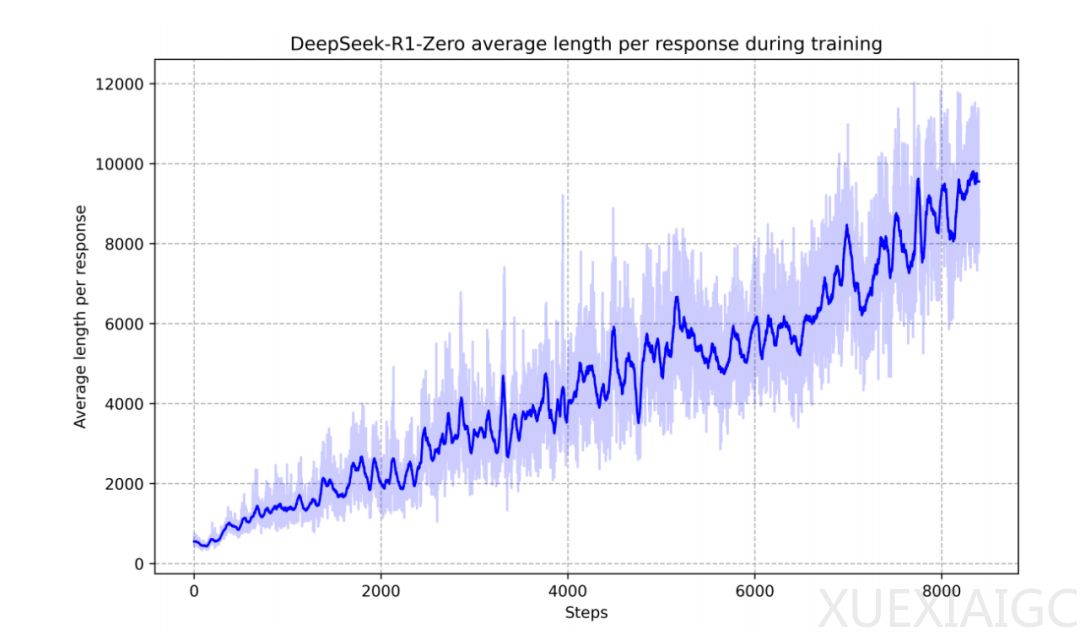
DeepSeek-R1系列模型,特别是R1-Zero,展示了无需监督学习的“顿悟时刻”,直接从DeepSeek-V3基座通过强化学习解锁o1级别的思维链能力,价格仅为o1的1/30。这一成果挑战了Meta之前的观点,即反思必须通过训练获得。DeepSeek-R1通过冷启动数据和多阶段训练流程,解决了模型在可读性和语言混合方面的问题,提升了推理性能。R1-Zero在训练集上的平均响应长度逐渐增加,自然地学会了通过增加思考时间来解决推理任务。
DeepSeek还证明了可以将较大模型的推理模式蒸馏成较小模型,性能优于通过强化学习在小模型上发现的推理模式。开源DeepSeek-R1及其API将使研究界受益,未来可能蒸馏出更优质的小体量模型。DeepSeek-R1-Distill-Qwen-32B模型在各类基准测试中表现优于OpenAI-o1-mini,标志着密集模型技术水平的新突破。
Kimi k1.5的技术重点在于通过长上下文扩展和改进的策略优化方法,结合多模态数据训练和长到短推理路径压缩技术,提升大模型在复杂推理和多模态任务中的性能和效率。k1.5将RL的上下文窗口扩展到128k,提出了基于长推理路径的强化学习公式,并采用在线镜像下降的变体进行稳健的策略优化。此外,k1.5在文本和视觉数据上联合训练,具有联合推理两种模态的能力。
知乎答主“ZHUI”和英伟达高级科学家Jim Fan都对Kimi和DeepSeek的成果进行了总结。他们认为,Kimi和DeepSeek的论文得出了相似的结论,即不需要复杂的蒙特卡洛树搜索、额外昂贵模型副本的价值函数和密集的奖励建模。两者的不同之处在于DeepSeek采用AlphaZero方法,而Kimi采用AlphaGo Master方法。DeepSeek的模型权重采用MIT开源许可,而Kimi尚未发布模型。Kimi在多模态性能方面表现出色,但在系统设计方面提供了更多细节。
DeepSeek R1的开源使其在全球社区里收获了更多的关注。在数学任务中,DeepSeek-R1的表现与OpenAI-o1-1217相当,大幅超越了其他模型。在编程算法任务中,以推理为导向的模型在基准测试中占据主导地位,DeepSeek-R1也展现出类似的趋势。DeepSeek R1的成功展示了强化学习飞轮效应的重大且持续增长,为开源项目树立了新的标杆。
原文和模型
【原文链接】 阅读原文 [ 2782字 | 12分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




