Karpathy称赞,从零实现LLaMa3项目爆火,半天1.5k star
文章摘要
【关 键 词】 Meta开源、llama3模型、代码生成、高质量、内部原理
Meta发布开源大模型llama3系列后,该模型在多个关键基准测试中表现优异,尤其在代码生成任务上处于领先地位。开发者们迅速开始尝试本地部署和实现,如llama3的中文实现和纯NumPy实现等。其中,名为Nishant Aklecha的开发者发布了一个从零开始实现llama3的存储库,该项目获得了包括大神Karpathy在内的广泛关注和认可。
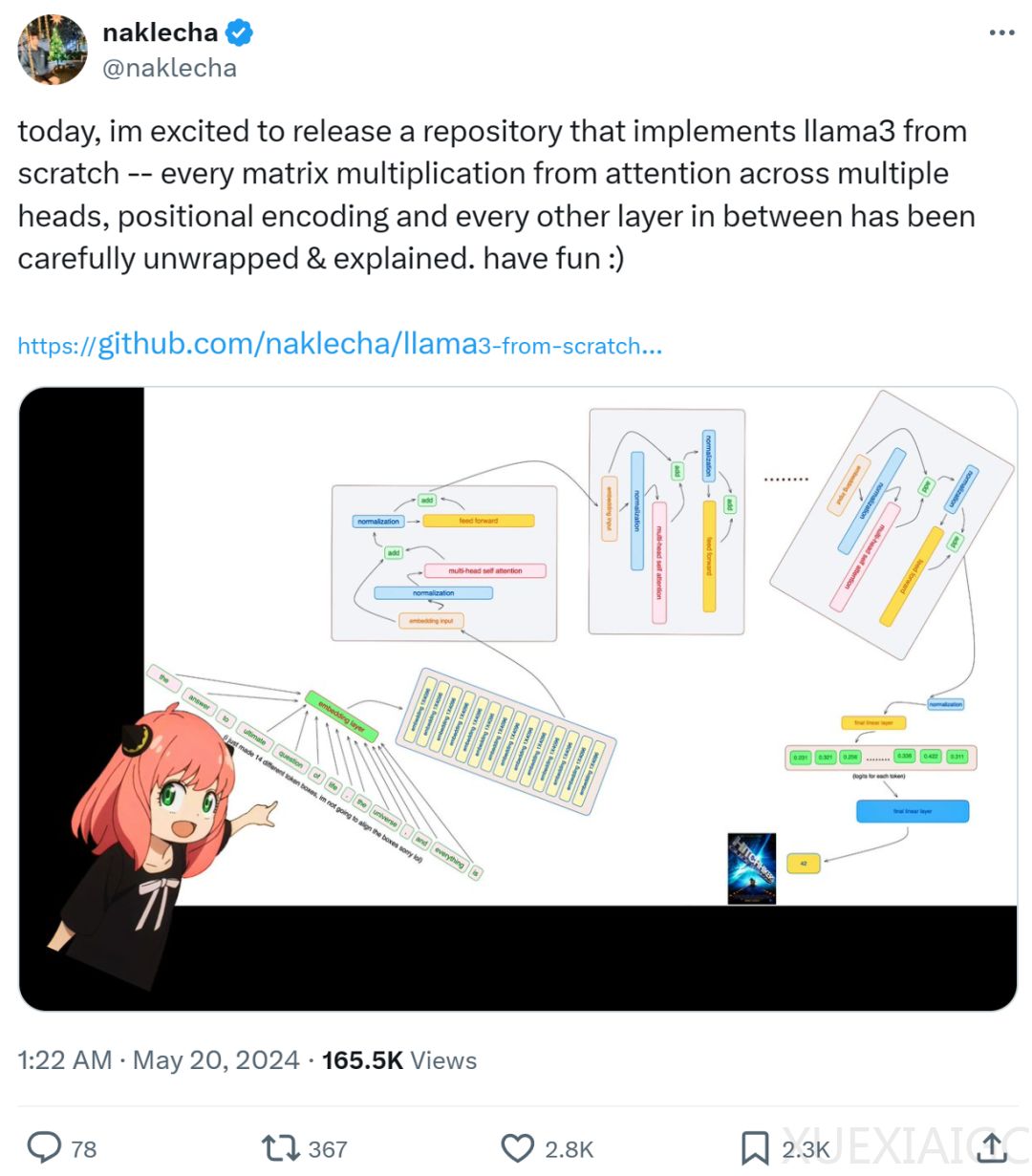
该项目在GitHub上迅速获得了1.5k的star,显示了其高质量和受欢迎的程度。项目中详细解释了跨多个头的注意力矩阵乘法、位置编码及每一层的实现。作者首先从Meta提供的llama3模型文件中加载张量,并采用了Karpathy的分词器实现方式。项目代码一次只读取一个张量文件,以逐层构建模型。
模型配置具有32个transformer层,每个多头注意力块包含32个头。作者使用了tiktoken库进行BPE分词处理,将文本转换为token,然后通过嵌入层转换为嵌入,并通过RMS算法进行归一化。在完成这些准备工作后,作者开始构建transformer的第一层,从模型文件中访问第一层,并保持归一化后的嵌入维度不变。
整个项目提供了详尽的步骤,指导开发者如何从零开始实现llama3模型,展示了模型的内部工作原理和各个组件的实现方式。这不仅有助于理解大型模型的工作机制,也为后续的研究和开发提供了有价值的资源。
原文和模型
【原文链接】 阅读原文 [ 4659字 | 19分钟 ]
【原文作者】 机器之心
【摘要模型】 glm-4
【摘要评分】 ★★★★★

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



