文章摘要
【关 键 词】 多模态、AI模型、视觉tokenizer、自回归、开源技术
智源研究院发布了原生多模态世界模型Emu3,该模型基于下一个token预测,无需依赖扩散模型或组合方法,能够完成文本、图像、视频三种模态数据的理解和生成。Emu3在图像生成、视频生成、视觉语言理解等任务中超过了SDXL、LLaVA、OpenSora等知名开源模型,且无需扩散模型、CLIP视觉编码器、预训练的LLM等技术,仅通过预测下一个token实现。
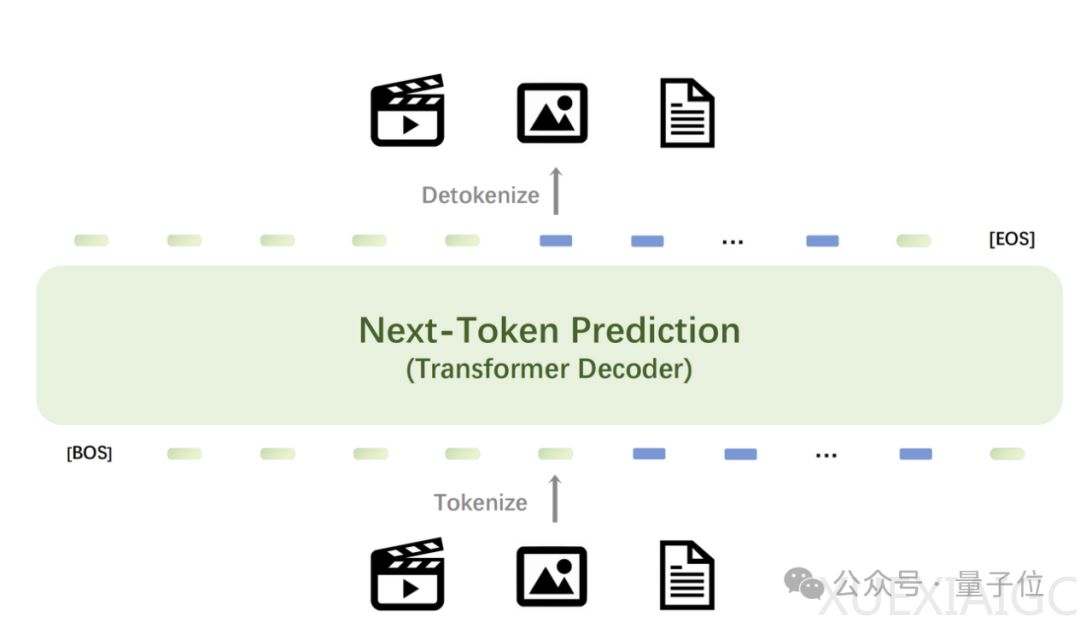
Emu3提供了强大的视觉tokenizer,将视频和图像转换为离散token,与文本tokenizer输出的离散token一起送入模型中。模型输出的离散token可转换为文本、图像和视频,为Any-to-Any任务提供统一研究范式。Emu3的下一个token预测框架灵活性使得直接偏好优化(DPO)可应用于自回归视觉生成,使模型与人类偏好保持一致。
Emu3研究结果证明,下一个token预测可作为多模态模型的强大范式,实现超越语言本身的大规模多模态学习,并在多模态任务中实现先进性能。通过将复杂的多模态设计收敛到token本身,能在大规模训练和推理中释放巨大潜力。Emu3为构建多模态AGI提供前景广阔的道路,已开源关键技术和模型。
Emu3一经上线便在社交媒体和技术社区引起热议,被认为是几个月来最重要的研究,非常接近拥有处理所有数据模态的单一架构。Emu3的统一方法将带来更高效、更多功能的AI系统,简化多模态AI的开发和应用,以及内容生成、分析和理解的新可能性。Emu3改写多模态人工智能规则,重新定义多模态AI,展示简单可以战胜复杂,使多模态AI未来更精炼强大。
Emu3在图像和视频的感知能力方面展现了强大能力,能够理解物理世界并提供连贯文本回复,不依赖基础LLM模型和CLIP。在图像生成方面,Emu3通过预测下一个视觉token生成高质量图像,支持灵活分辨率和不同风格。在视频生成方面,Emu3通过预测序列中的下一个token因果性生成视频,不同于使用视频扩散模型从噪声生成视频。在视频预测方面,Emu3可以自然扩展视频并预测接下来发生什么,模拟物理世界中环境、人和动物。
Emu3的技术细节包括在语言、图像和视频混合数据模态上从头开始训练,使用与Aquila模型相同的语言数据,构建大型图像文本数据集,收集涵盖多个类别的视频。Emu3在SBER-MoVQGAN基础上训练视觉tokenizer,将视频片段或图像编码成离散token。Emu3保留主流大语言模型网络架构,扩展嵌入层以容纳离散视觉token,使用RMSNorm归一化,GQA注意力机制等技术。在预训练过程中,定义多模态数据格式,新增特殊token合并文本和视觉数据,为训练过程创建类似文档的输入。
原文和模型
【原文链接】 阅读原文 [ 4341字 | 18分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



