文章摘要
【关 键 词】 FlashAttention-3、性能提升、FP16、FP8、Hopper架构
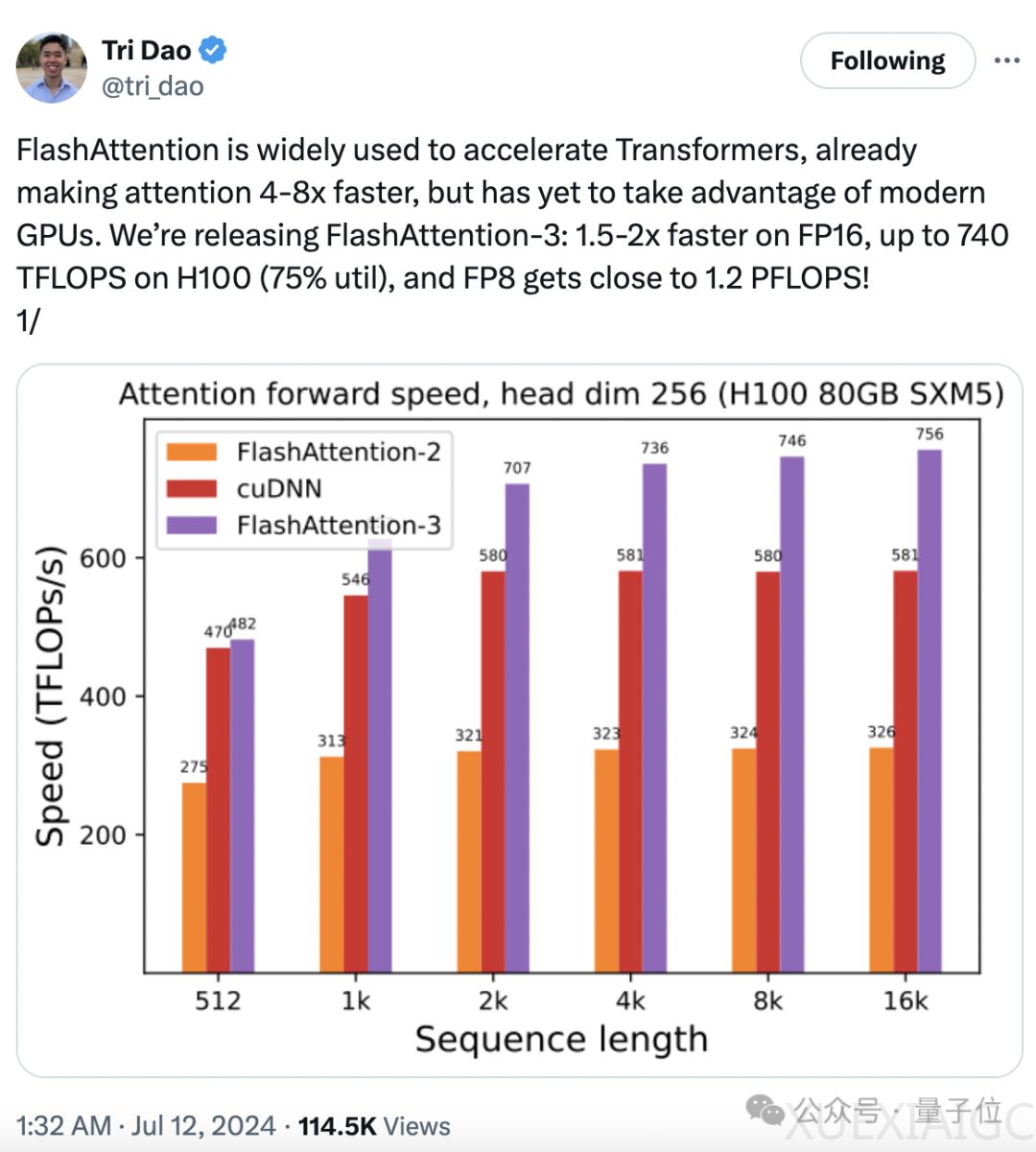
FlashAttention-3,一种用于大模型训练和推理的算法,经过一年的开发,已经推出了第三代。这一升级版本在训练速度上实现了1.5至2倍的提升,在FP16(16位浮点数)计算下,吞吐量达到了740TFLOPs/s,占理论最大吞吐量的75%,相较于之前的35%有了显著提升。在FP8(8位浮点数)计算下,速度接近1.2PFLOPs/s,同时在FP8下的误差比标准Attention减少了2.6倍。
FlashAttention-3的开发得到了英伟达、Meta、谷歌等公司的合作与支持,特别是针对英伟达的H100芯片进行了专门的优化。该算法将继续开源,已集成至PyTorch和Hugging Face平台。FlashAttention-3的发布得到了业界的广泛关注,前Stable Diffusion负责人Emad预测,使用FlashAttention-3可以将4090的FP8计算吞吐量提升至700+TFLOPs。
FlashAttention-3充分利用了英伟达Hopper架构的特点,通过IO感知优化和分块处理,解决了传统注意力机制在处理长序列时内存访问频繁和算法复杂度指数级增长的问题。算法通过将数据从高带宽内存(HBM)加载到片上内存(SRAM)中执行计算,减少了内存读写操作次数。分块处理则是将输入序列分成小块,每次只处理一个小块的数据,降低了内存使用和计算复杂度。
FlashAttention-3的技术升级包括三个方面:首先,针对Hopper架构的Tensor Core异步性,引入了“生产者-消费者”编程模型,利用张量内存加速器(TMA)实现数据的异步加载。其次,通过warp专门化技术和“乒乓调度”策略,实现了计算的重叠和GPU利用率的提升。最后,通过引入内存布局转换技术、分块量化和非相干处理技术,在FP8精度下实现了更高的计算精度。
在性能测试方面,FlashAttention-3在前向传播和后向传播的速度上均优于FlashAttention-2和标准Attention,尤其在中长序列上的表现超过了专门为H100优化的cuDNN。消融实验和FP8注意力准确性测试进一步证实了FlashAttention-3的技术改进带来了显著的加速效果和更高的计算精度。
目前,FlashAttention-3的研究工作主要集中在Hopper架构上,未来将推广到其他硬件平台。除了英伟达提供的技术支持外,Meta、Together AI和普林斯顿大学也为研究提供了计算支持。
原文和模型
【原文链接】 阅读原文 [ 2400字 | 10分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



