DeepSeek R1 API实测,哪家服务商最靠谱?
文章摘要
【关 键 词】 AI模型、云平台测评、性能指标、供应商评估、开发者工具
国内云平台对DeepSeek R1/V3模型的服务质量呈现显著差异,测试发现关键性能指标直接影响实际应用效果。区分供应商的核心标准包括模型版本真实性、上下文窗口容量和TPM限制,其中6000亿参数的原生模型、64K以上窗口和10万以上TPM是合格供应商的基准线。测试显示部分厂商通过”蒸馏版”模型或低配置参数降低服务质量,这类服务仅适用于简单对话场景。
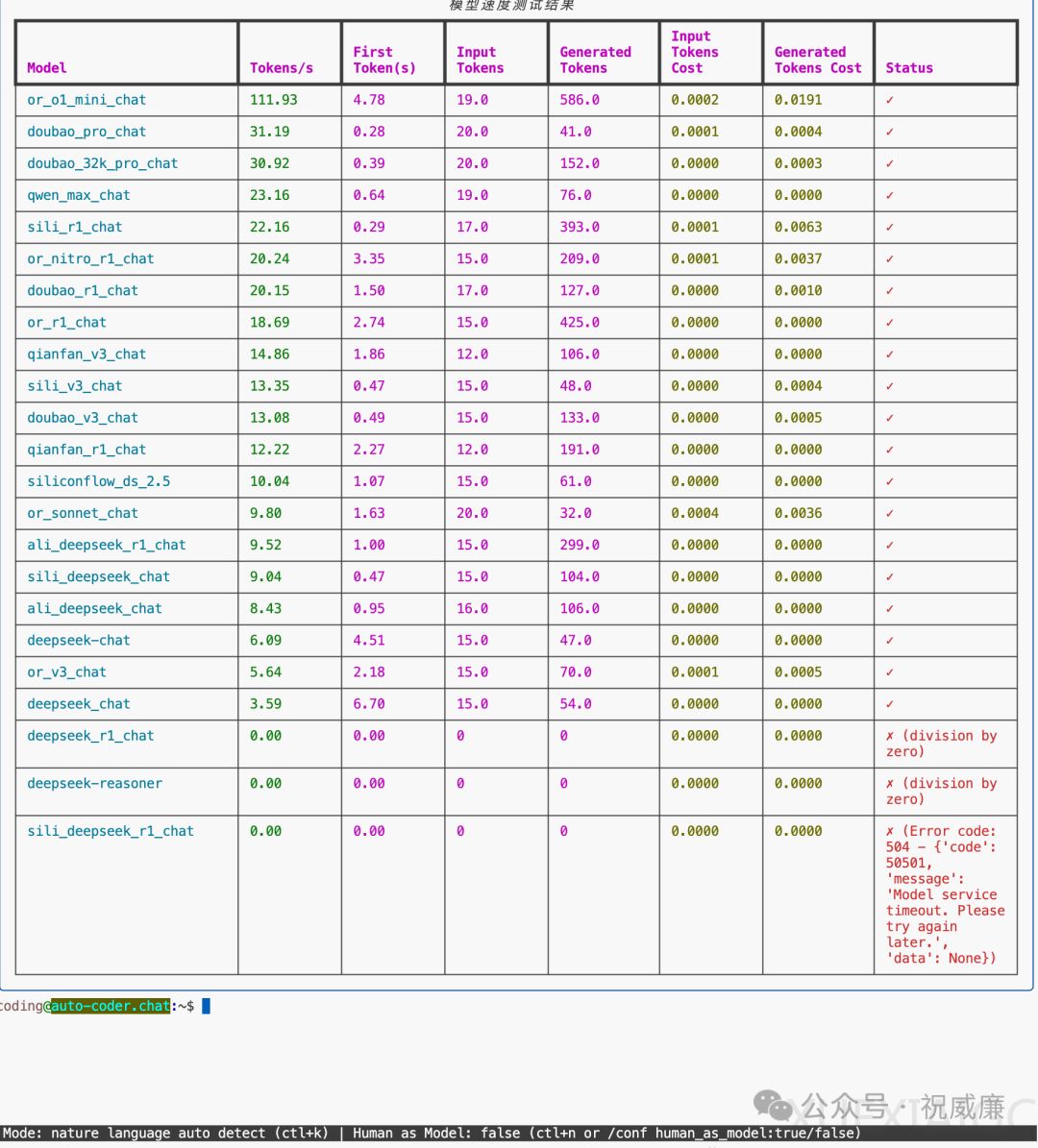
在速度测试环节,硅基流动和火山方舟在关键指标上表现突出。小输入场景下(100token以内),R1模型生成速度前三名为硅基流动(22t/s)、OpenRouter(20.24t/s)和火山方舟(20.15t/s);V3模型则以百度千帆(14.86t/s)领先。首token响应时间方面,硅基流动以0.2秒的极低延迟保持优势。大输入测试(14000token)中,OpenRouter的R1模型以29.55t/s居首,火山方舟和硅基流动分列二三位,而百度千帆因TPM限制直接报错。
测试方法论揭示性能指标受三大因素影响:输入长度、测试时段和用户规模。实际应用场景中,上下文窗口容量不足将导致复杂任务无法执行,如某平台4K窗口仅支持简单对话。开发者可通过auto-coder工具自行验证,支持小输入测试(/models /speed-test)和长上下文测试(/models /speed-test /long-context),测试轮次可自定义调整。
最终评估显示,火山方舟和硅基流动在技术实力和服务质量上处于领先地位,其响应速度、处理能力与官方模型对齐度较高。开发者选择服务商时需综合考量模型真实性、处理能力和资源供给,避免受限于表面参数而影响实际开发效果。测试工具链的开放也为开发者自主验证服务商承诺提供了技术保障。
原文和模型
【原文链接】 阅读原文 [ 1925字 | 8分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek-r1
【摘要评分】 ★★★☆☆


相关文章




