DeepSeek R1 之后,重新理解推理模型
文章摘要
【关 键 词】 推理模型、Scaling Law、强化学习、模型优化、DeepSeek-R1
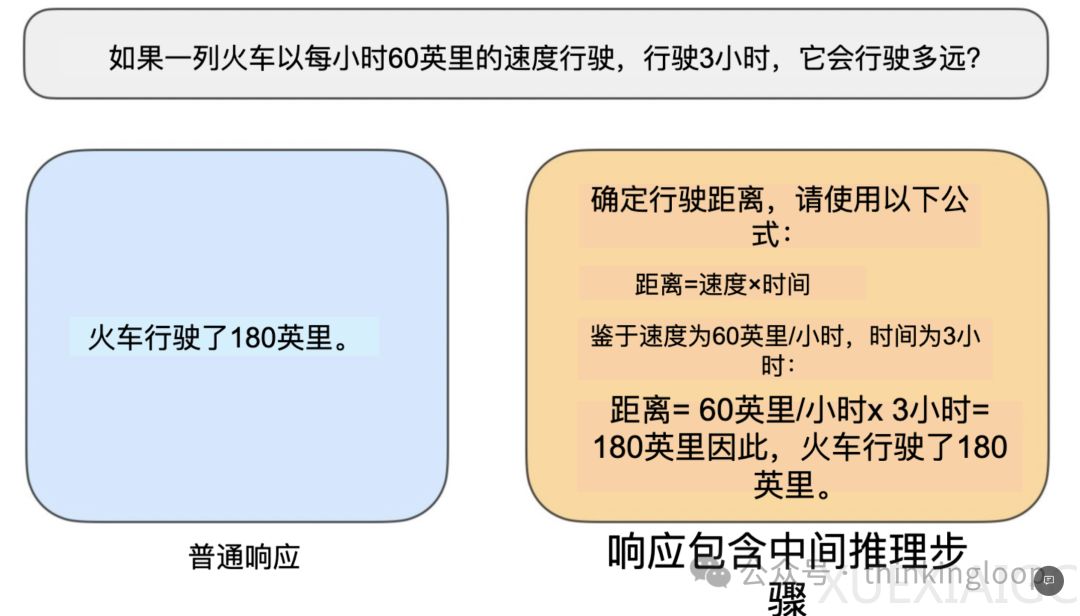
对推理模型的技术发展与行业应用分析显示,这类模型通过多步骤生成和中间思考过程解决复杂任务,其核心优势体现在解谜、数学证明与编码挑战等场景。“推理”被定义为需要复杂多步骤生成并包含中间思考环节的问题解决过程,例如火车速度计算需识别变量关系而非直接输出结果。传统模型仅提供简短答案,而推理模型则通过思维链(CoT)展示中间推导步骤,这种设计使其在特定领域表现突出,但同时也带来成本增加与“过度思考”导致的错误风险。
DeepSeek推出的R1系列模型展示了技术路径的多样性:DeepSeek-R1-Zero采用纯强化学习(RL)跳过监督微调阶段,通过准确性奖励(如LeetCode编译验证)和格式奖励(LLM评委评估)驱动模型生成结构化思考步骤;旗舰模型DeepSeek-R1在此基础上叠加监督微调(SFT)与RL优化;而R1-Distill通过大模型输出训练小模型实现推理能力迁移,尽管部分蒸馏版本在特定任务(如编码)表现优异,但整体性能仍与完整版存在差距。这种分层策略揭示了RL+SFT组合在提升模型性能上的有效性,而蒸馏技术更适合模型轻量化而非前沿突破。
推理时间扩展(Inference-time scaling)作为关键优化手段,通过增加生成步骤提升输出质量,例如思维链提示或多数投票策略。OpenAI的o1/o3模型可能结合了该技术与RL训练,但DeepSeek-R1通过更优基模型实现了高性价比。值得注意的是,这类技术虽能提升复杂问题处理能力,却显著增加计算成本,尤其在处理简单任务时性价比低下。
行业趋势方面,2024年大模型专业化趋势加速,推理模型作为细分方向需与RAG、代码助手等应用场景协同。当前挑战包括:企业级应用中如何选择适用场景(如深度搜索与机器思维链的结合)、Agent框架的长链路任务支持能力,以及模型幻觉风险的控制。机器思维链替代人类思考的可行性仍需验证,尤其在“拒绝回答”机制成熟前,过度依赖推理模型可能引发信息可信度问题。
技术路径的探索揭示了两大方向:纯RL训练有助于理解推理的涌现特性,而RL+SFT组合更具实用价值。未来模型开发需平衡创新性与工程可行性,同时关注领域专业化需求——推理模型不会取代其他LLM应用,而是在特定复杂任务中形成互补。
原文和模型
【原文链接】 阅读原文 [ 5718字 | 23分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章




