DeepSeek用的GRPO占用大量内存?有人给出了些破解方法
文章摘要
【关 键 词】 GRPO、显存优化、参数微调、强化学习、大模型训练
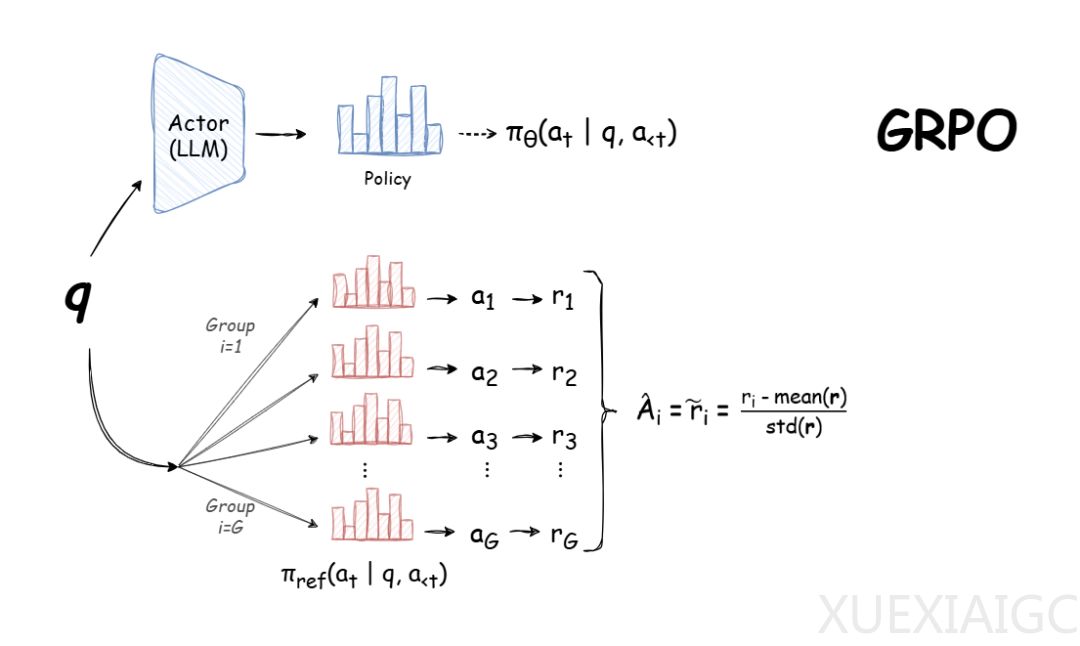
群组相对策略优化(GRPO)作为一种在线学习算法,通过使用训练过程中由模型自身生成的数据进行迭代改进,已因其高效性和易用性成为大型语言模型强化学习中的重要方法。它旨在最大化生成补全的优势函数,同时确保模型保持在参考策略附近。尽管GRPO提供了强大的训练能力,但其内存需求较高,特别是在GPU资源有限的情况下,对显存的占用成为关键挑战。
实验表明,训练大型语言模型时所需的显存受多种因素影响,包括模型大小、是否使用完全微调或参数高效微调(PEFT)、以及超参数设置。全参数微调通常需要显著更多的显存,而PEFT(如LoRA)能够有效降低内存需求。对于特定硬件(如16GB显存的RTX 3080移动版),采用8-bit优化器和梯度检查点技术可以大幅减少显存占用,但后者会导致训练速度减慢20-30%。
在实际应用中,GRPO涉及多个模型(策略模型、参考模型和奖励模型)的推理计算,这进一步增加了显存压力。为应对这一问题,可以通过调整batch size、gradient_accumulation_steps、num_completions等超参数来平衡显存使用与性能表现。例如,作者建议在内存受限时将num_generations设置为4,这既能减少显存消耗,又可保持较好的训练效果。
实验数据还显示,使用GRPO对LLM进行微调可以在较短时间内显著提升性能。在一个基于Llama 3.2的10亿参数模型的测试中,模型在保留测试集上的准确率从19%提升至40.5%,验证了GRPO在提升模型推理能力方面的潜力。此外,像trl这样的库简化了GRPO的实现过程,开发者可通过定义奖励函数和配置超参数快速启动微调任务。
总体而言,在硬件资源有限的情况下,开发者需根据显存预算合理选择模型规模和训练方式,并借助内存优化技术(如8-bit优化器和梯度检查点)实现对大模型的高效训练。这些发现为在资源受限环境中应用GRPO提供了明确的技术路径和实践指导。
原文和模型
【原文链接】 阅读原文 [ 2174字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen-max-2025-01-25
【摘要评分】 ★★★★★


相关文章




