文章摘要
GRPO训练作为一种基于PPO算法的改进方法,近年来在强化学习领域引起了广泛关注。GRPO通过采样替代value model的方式,简化了训练过程,提升了稳定性和可维护性。然而,GRPO训练在实际应用中仍面临诸多挑战,如训练速度慢、集群配置复杂、多模态扩展能力不足等。为此,ModelScope魔搭社区推出了基于MS-SWIFT和EvalScope框架的GRPO全链路解决方案,旨在为开源社区提供高效的支持。
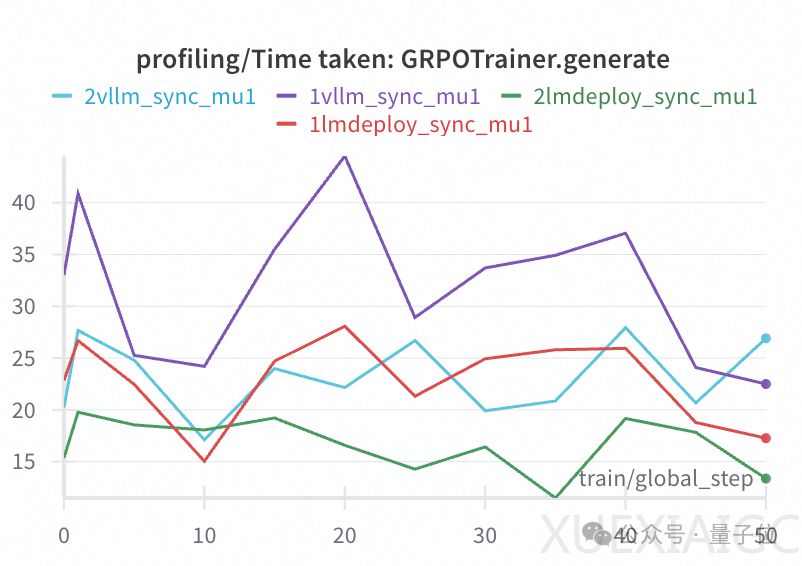
优化采样效率是提升GRPO整体训练速度的核心所在。GRPO训练的耗时主要集中在采样和训练阶段,尤其是采样部分,由于单query的采样数较大,对推理引擎提出了极高的要求。SWIFT框架通过多实例数据并行采样、异步采样等技术,显著提升了采样效率。多实例数据并行采样允许训练资源根据实际需求倾斜分配,从而减少采样耗时对训练速度的影响。异步采样则通过在训练时同时进行采样,避免了采样和训练交替进行时的资源闲置问题,进一步提升了训练效率。
在模型placement方面,SWIFT支持训练和rollout使用同一资源组,并通过vLLM的sleep模式减少显存占用。此外,SWIFT还引入了LMDeploy推理框架的支持,该框架在推理速度和权重加载速度上表现出色,进一步加速了整体训练过程。通过多轮更新机制,SWIFT减少了采样频率,使采样和训练的资源分配更加均衡,从而提升了训练速度。
在多模态GRPO训练方面,SWIFT框架已经支持图文、视频、音频等多模态模型的训练。通过在数据集中指定多模态字段,GRPO能够将多模态内容输入模型进行强化训练。实验表明,SWIFT在多模态计数任务上表现优异,模型能够准确输出计数结果,并在任务成功率上实现了显著提升。
EvalScope框架作为魔搭社区推出的大模型评测工具,提供了全面的推理性能评测能力,并支持评测结果的可视化。针对Reasoning模型在推理过程中存在的Underthinking和Overthinking问题,EvalScope实现了思考效率评测能力,能够从token效率、思考长度、子思维链数量和准确率四个方面评估模型的推理效率。
通过整合多种训练加速技术,SWIFT框架在GRPO的中小集群训练效率上实现了显著提升。实验结果表明,SWIFT在八卡环境下的训练耗时显著低于其他框架,并且模型在训练过程中成功实现了奖励值的提升。未来,SWIFT将继续扩展对Megatron结构模型的支持,并在多模态Reasoning评测领域进行深入探索。
原文和模型
【原文链接】 阅读原文 [ 3812字 | 16分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章




