DeepMind用语言游戏让大模型学AlphaGo自我博弈,数据限制不存在了
文章摘要
【关 键 词】 苏格拉底学习、自我完善、人工智能、语言游戏、递归增强
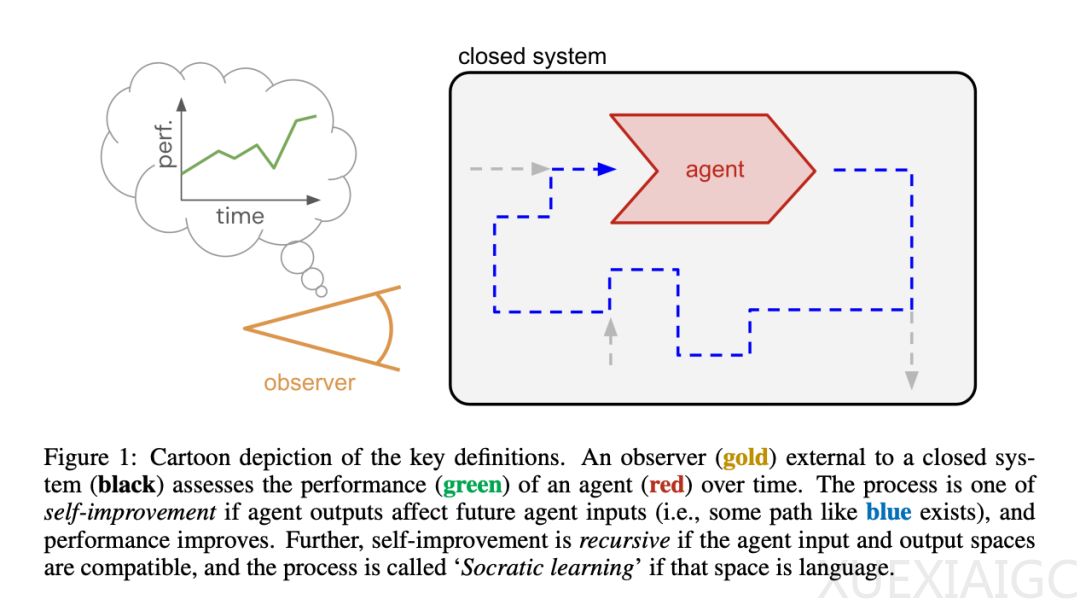
Google DeepMind 的研究团队提出了一种名为“苏格拉底式学习”的人工智能自我完善新方法,该方法通过结构化的“语言游戏”实现AI系统的递归自我增强,超越初始训练数据的限制。这一框架建立在封闭、自给自足的环境之上,AI系统无需外部数据即可运行,满足反馈与目标一致、广泛的数据覆盖范围和足够的计算资源三个关键条件,促进独立学习,为实现通用人工智能(AGI)提供可扩展的途径。
苏格拉底式学习的核心在于智能体之间的结构化交互,通过“语言游戏”解决问题并接收反馈,无需人工输入。递归结构使系统能够自主创建和开局新游戏,解锁更抽象的解决问题的能力并扩展其能力。AI自我改造的创新在于智能体不仅能从环境中学习,还能重新配置其内部系统,消除固定架构的限制,为性能改进奠定基础。
该研究强调了苏格拉底式学习作为创造真正自主、自我完善的人工智能的变革性步骤的潜力。智能体内部元素分为固定元素、瞬态元素和学习元素,其中学习元素会根据反馈信号变化。自我完善的三个必要条件是反馈、覆盖度和规模,其中覆盖度和反馈是原则上的可行性,规模是实践上的可行性。递归自我完善中智能体的输入和输出是兼容的,输出成为未来的输入,这种类型的递归是许多开放式过程的属性,开放式改进是ASI的核心特征。
苏格拉底式学习的本质局限性在于覆盖和反馈条件原则上适用于苏格拉底式学习,但仍然是不可还原的。覆盖条件意味着系统必须不断生成数据,同时保持或扩大多样性。反馈条件要求系统持续产生关于智能体输出的反馈,并与观察者的评估指标保持一致。纯粹的苏格拉底式学习是可能的,但需要广泛的数据生成和强大且一致的批评能力。当这些条件都具备时,其潜在改进的上限受到应用资源量的限制。
研究者认为,AI的训练可以借鉴维特根斯坦的语言游戏概念,语言游戏定义为一种互动协议,指定智能体之间的互动和游戏结束时的标量评分函数。语言游戏满足了苏格拉底式学习的两个主要需求,即无限制的交互式数据生成和自我博弈,同时自动提供伴随的反馈信号。许多常见的LLM交互范式也可以被很好地表示为语言游戏,如辩论、角色扮演等。苏格拉底式学习的整个过程就是一个元游戏,它安排了智能体玩的语言游戏并从中学习。
递归自我改造是智能体的行为会改变其自身的内部结构,而不仅仅是影响其输入流。这种类型的智能体具有最高的能力上限,由于渐进性能受到其固定结构的限制,解冻部分结构并使其可修改只会增加上限。现代LLM在代码理解和生成方面的能力正在改变竞争环境,可能很快就会将这些想法从空洞转向关键。
原文和模型
【原文链接】 阅读原文 [ 4375字 | 18分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


