文章摘要
【关 键 词】 人工智能、绘画生成、提示词、高效操控、图像质量
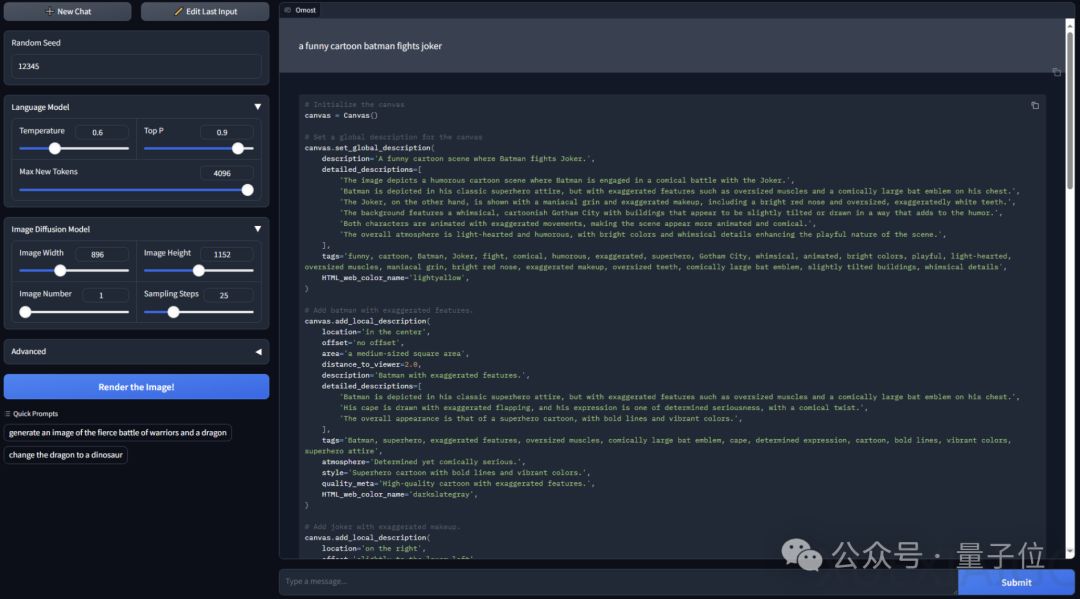
量子位报道,ControlNet作者Lvmin Zhang推出了新项目Omost,旨在通过人工智能技术解决AI绘画中的提示词写作难题。用户只需提供一句简单的提示词,Omost即可自动“构图”生成相应的图像。例如,输入“一幅有趣的卡通蝙蝠侠与小丑战斗的图画”,系统便能生成相应的画面。
Omost这个名字有两层含义:一是与英文单词almost(几乎)发音相似,表示每次使用Omost后,用户所需的图像几乎就完成了;二是“O”代表“omni”(全能的),而“most”表示希望最大限度地利用它。项目采用了基于Llama3和Phi3变体的三种大模型,使AI能够详细地指定图像中各个元素的位置和大小,甚至可以修改已生成图像中的某个元素。
具体实现上,Omost通过划分图像的3×3位置和偏移量,定义了729个不同的边界框,几乎涵盖了图像中元素的所有常见可能位置。此外,通过distance_to_viewer和HTML_web_color_name参数调整视觉表现,实现了对图像生成更精细的控制。Lvmin Zhang还提供了一个基于注意力操纵的Omost LLM的baseline渲染器,并探讨了区域引导的扩散系统的实现选择。
为了进一步提升提示理解,Lvmin Zhang提出了“提示前缀树”概念,通过合并任意子提示,改进结果和提示描述。这个项目已经开放了源代码和Demo,供感兴趣的用户尝试。
总的来说,Omost通过简化用户提示词写作过程,实现了对AI绘画的高效操控,提高了图像生成的质量和效率。
原文和模型
【原文链接】 阅读原文 [ 1961字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 glm-4
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...


