CNN、Transformer、Uniformer之外,我们终于有了更高效的视频理解技术
文章摘要
【关 键 词】 视频理解、时空建模、Mamba模型、长视频、性能提升
视频理解技术旨在准确把握视频中的时空信息,但面临着短视频片段的时空冗余和复杂时空依赖关系的双重挑战。传统的三维卷积神经网络(CNN)和视频Transformer在解决单个挑战方面表现出色,但在同时应对两者时存在不足。近期提出的UniFormer、S4、RWKV和RetNet等低成本方案为视觉模型提供了新思路,而Mamba模型凭借其选择性状态空间模型(SSM)在保持线性复杂度的同时,有效平衡了长期动态建模的需求。
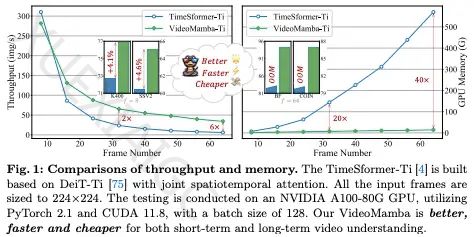
受Mamba启发,研究者们提出了VideoMamba,这是一种专为视频理解设计的纯SSM模型。VideoMamba结合了卷积和注意力机制的优势,适用于高分辨率长视频的动态时空背景建模。通过一系列评估,VideoMamba在可扩展性、短期动作识别敏感性、长视频理解优越性和与其他模态兼容性等方面展现出显著能力。尤其在长视频理解方面,VideoMamba的运行速度和GPU内存需求均优于现有模型。
VideoMamba采用3D卷积将输入视频投影到多个时空补丁,再通过双向3D扫描进行时空建模。模型中的B-Mamba层使用与Mamba相同的超参数设置,通过自蒸馏策略解决过拟合问题。实验结果表明,VideoMamba在ImageNet-1K数据集上的性能优于其他各向同性架构,并在短期视频数据集上展现出与顶尖模型相当的性能。在长视频理解任务中,VideoMamba相对于传统方法实现了显著的性能提升。此外,VideoMamba在零样本视频检索性能上也优于基于ViT的模型。
总之,VideoMamba凭借其高效性和有效性,成为长视频理解领域的重要基石。所有相关代码和模型已开源,以促进未来研究的发展。
原文和模型
【原文链接】 阅读原文 [ 2348字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章


