文章摘要
【关 键 词】 统计显著性、超总体概念、聚类标准误差、全方差定律、模型比较
在大语言模型(LLM)的评估领域,传统的基准测试方法往往忽视了统计显著性,仅依赖于表面的得分高低来判断模型性能,这可能导致不准确的结论。为了解决这一问题,Anthropic提出了引入严谨的统计思维,通过构建全面的分析框架来量化评估结果的精确性,并判断模型间差异的统计显著性。
评估框架中引入了“超总体”概念,即包含所有可能问题的宏观概念,将具体问题视为从更大的问题集合中随机抽取的样本。这种宏观视角有助于更准确地估计模型性能。理论基础中,每个问题的得分被分解为均值部分和零均值随机部分,利用中心极限定理估计均值的标准误差,即使评估得分的分布未知。
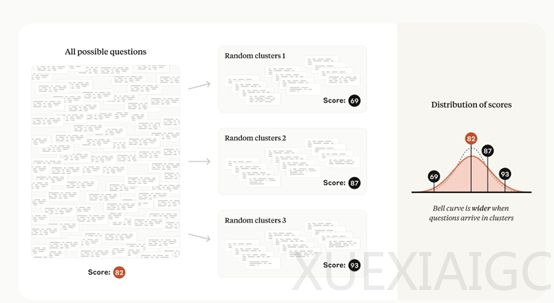
然而,评估中的问题并非总是独立,如阅读理解评估中多个相关问题可能基于同一文本段落,导致问题的抽取非独立。为解决这一问题,引入了聚类标准误差的概念,用于处理问题聚类中的依赖和相关结构。
方差的降低是提高估计精度的关键。方差可以分解为从超总体中选择问题的方差和所选问题的得分的均值条件方差,这种分解遵循全方差定律。
研究人员设计了一个假设性实验,比较了两个虚构模型“Galleon”和“Dreadnought”在三个非虚构评估上的表现。通过计算标准误差和95%置信区间,可以得出Galleon在MATH评估上的表现显著优于Dreadnought,而Dreadnought在HumanEval和MGSM评估上的表现显著优于Galleon。这些案例分析展示了计算标准误差和置信区间的重要性,它们能够提供更丰富的信息,帮助研究者更准确地评估模型在不同任务上的表现。
原文和模型
【原文链接】 阅读原文 [ 1324字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


